
Make Your Compute Server Robust and Scalable
First published in JavaWorld, June 2000
In "Make Room for JavaSpaces, Part 2: Build a compute server with JavaSpaces" you saw how to build a simple general-purpose compute server using the JavaSpaces technology. Recall that a compute server is a powerful, all-purpose computing engine that accepts tasks, computes them, and returns results. In that design, a master process breaks down a large, compute-intensive problem into smaller tasks -- entries that describe the task and contain a method to perform the necessary computation -- and writes them into a space. In the meantime, worker processes watch the space and retrieve tasks as they become available, compute them, and write the results back to the space, from which the master will retrieve them at some point.
Simple as it is, the compute server has some impressive qualities. First, it is general purpose: You can simply send it new tasks whenever you want and know they will be computed. There's no need to bring the compute server down or install new task code on various machines, since executable content is built into the task entries themselves. Second, the compute server scales automatically: As new workers come along, they can pick up tasks and join in the computation, thereby speeding up the overall solution. Workers can come and go from the compute server, without requiring code changes or reconfiguration. And finally, the compute server is well suited to load balancing: workers pick up tasks whenever they can, so the workload is balanced naturally among workers on slower and faster machines.
Despite its admirable properties, the compute server still isn't quite ready for the real world yet. In this article, I'll show you how to make two big improvements to gear the system up for real-world use. If you read Part 4 of this series, you've probably guessed that one of the compute server's weaknesses is that it neglects to account for the presence of partial failure. Armed with what you know about Jini transactions from that article, I'll now have you revisit the compute server code and show you how to make it more fault tolerant. Another potential shortcoming of the compute server is its use of a single JavaSpace, running on a single CPU. Under some circumstances, reliance on one space may introduce a bottleneck, so I'll revisit the compute server code to show how you can make use of multiple spaces to allow for greater scalability.
Adding Transactions to the Worker
Take another look at the original worker code from the compute server and see why it's not fault tolerant:
public class Worker {
private JavaSpace space;
public static void main(String[] args) {
Worker worker = new Worker();
worker.startWork();
}
public Worker() {
space = SpaceAccessor.getSpace();
}
public void startWork() {
TaskEntry template = new TaskEntry();
for (;;) {
try {
TaskEntry task = (TaskEntry)
space.take(template, null, Long.MAX_VALUE);
Entry result = task.execute();
if (result != null) {
space.write(result, null, 1000*60*10);
}
} catch (Exception e) {
System.out.println("Task cancelled");
}
}
}
}
After gaining access to a space and calling the startWork method, the worker repeatedly takes a task entry from the space, computes the task, and writes the result to the space. Note that take and write are both performed under a null transaction, which means each of those operations consists of one indivisible action (the operation itself). Step back and think about one scenario that can occur in networked environments, which are prone to partial failure. Consider the case in which a worker removes a task and begins executing it, and then failure occurs (maybe the worker dies unexpectedly or gets disconnected from the network). In this scenario, the task entry is lost for good, and as a result the overall computation won't ever be fully solved.
You can make the worker more robust by using transactions. (The complete code for the compute server that has been reworked with transactions can be found in Resources and forms the javaworld.simplecompute2 package.) First you'll modify the worker's constructor to obtain a TransactionManager proxy object and assign it to the variable mgr, and you'll define a getTransaction method that creates and returns new transactions:
public class Worker {
private JavaSpace space;
private TransactionManager mgr;
. . .
public Worker() {
space = SpaceAccessor.getSpace();
mgr = TransactionManagerAccessor.getManager();
}
public Transaction getTransaction(long leaseTime) {
try {
Transaction.Created created =
TransactionFactory.create(mgr, leaseTime);
return created.transaction;
} catch(RemoteException e) {
e.printStackTrace();
return null;
} catch(LeaseDeniedException e) {
e.printStackTrace();
return null;
}
}
}
Most of the getTransaction method should be familiar to you after you have read Make Room for JavaSpaces, Part 4. Note that the method has a leaseTime parameter, which indicates the lease time that you'd like the transaction to have.
Now let's modify the startWork method to add support for transactions:
public void startWork() {
TaskEntry template = new TaskEntry();
for (;;) {
// try to get a transaction with a 10-min lease time
Transaction txn = getTransaction(1000*10*60);
if (txn == null) {
throw new RuntimeException("Can't obtain a transaction");
}
try {
try {
// take the task under a transaction
TaskEntry task = (TaskEntry)
space.take(template, txn, Long.MAX_VALUE);
// perform the task
Entry result = task.execute();
// write the result into the space under a transaction
if (result != null) {
space.write(result, txn, 1000*60*10);
}
} catch (Exception e) {
System.out.println("Task cancelled:" + e);
txn.abort();
}
txn.commit();
} catch (Exception e) {
System.out.println("Transaction failed:" + e);
}
}
Each time startWork iterates through its loop, it calls getTransaction to attempt to get a new transaction with a lease time of 10 minutes. If an exception occurs while creating the transaction, then the call to getTransaction returns null, and the worker throws a runtime exception. Otherwise, the worker has a transaction in hand and can continue with its work.
First, you call take (passing it the transaction) and wait until it returns a task entry. Once you have a task entry, you call the task's execute method and assign the returned value to the local variable result. If the result entry is non-null, then you write it into the space under the transaction, with a lease time of 10 minutes.
In this scenario, three things could happen. One possibility is that the operations complete without throwing any exceptions, and you attempt to commit the transaction by calling the transaction's commit method. By calling this method, you're asking the transaction manager to commit the transaction. If the commit is successful, then all the operations invoked under the transaction (in this case, the take and write) occur in the space as one atomic operation.
The second possibility is that an exception occurs while carrying out the operations. In this case, you explicitly ask the transaction manager to abort the transaction in the inner catch clause. If the abort is successful, then no operations occur in the space -- the task still exists in the space as if it hadn't been touched.
A third possibility is that an exception occurs in the process of committing or aborting the transaction. In this case, the outer catch clause catches the exception and prints a message, indicating that the transaction failed. The transaction will expire when its lease time ends (in this case after 10 minutes), and no operations will take place. The transaction will also expire if this client unexpectedly dies or becomes disconnected from the network during the series of calls.
Now that you've made the worker code robust, let's turn to the master code and show how you can improve it as well.
Adding Transactions to the Master
Recall the Master code from the compute server example, which calls the generateTasks method to generate a set of tasks and then calls the collectResults method to collect results:
public class Master {
private JavaSpace space;
public static void main(String[] args) {
Master master = new Master();
master.startComputing();
}
private void startComputing() {
space = SpaceAccessor.getSpace();
generateTasks();
collectResults();
}
private void generateTasks() {
for (int i = 0; i < 10; i++) {
writeTask(new AddTask(new Integer(i), new Integer(i)));
}
for (int i = 0; i < 10; i++) {
writeTask(new MultTask(new Integer(i), new Integer(i)));
}
}
private void collectResults() {
for (int i = 0; i < 20; i++) {
ResultEntry result = takeResult();
if (result != null) {
System.out.println(result);
}
}
}
private void writeTask(Command task) {
try {
space.write(task, null, Lease.FOREVER);
} catch (Exception e) {
e.printStackTrace();
}
}
protected ResultEntry takeResult() {
ResultEntry template = new ResultEntry();
try {
ResultEntry result = (ResultEntry)
space.take(template, null, Long.MAX_VALUE);
return result;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
You'll notice in writeTask that the write occurs under a null transaction. If the write returns without throwing an exception, then you can trust that the entry was committed to the space. But if a problem occurs during the operation and an exception is thrown, you can't know for sure whether or not the task entry was written to the space. If a RemoteException is thrown (which can occur whenever a space operation communicates with the remote JavaSpace service), the task entry may or may not have been written. If any other type of exception is thrown, then you know the entry wasn't written to the space.
The master isn't very fault tolerant, since you never know for sure whether or not a task is written successfully into the space. And if some of the tasks don't get written, the compute server isn't going to be able to completely solve the parallel computation on which it's working. To make Master more robust, you'll first add the convenient getTransaction method that you saw previously. You'll also modify the writeTask to make use of transactions and to return a Boolean value that indicates whether or not it wrote the task:
private boolean writeTask(Command task) {
// try to get a transaction with a 10-min lease time
Transaction txn = getTransaction(1000*10*60);
if (txn == null) {
throw new RuntimeException("Can't obtain a transaction");
}
try {
try {
space.write(task, txn, Lease.FOREVER);
} catch (Exception e) {
txn.abort();
return false;
}
txn.commit();
return true;
} catch (Exception e) {
System.err.println("Transaction failed");
return false;
}
}
First, writeTask tries to obtain a transaction with a 10-minute lease by calling getTransaction, just as you did in the worker code. With the transaction in hand, you can retrofit the write operation to work under it. This time when you call write, you supply the transaction as the second argument.
Again, three things can happen as this code runs. If the write completes without throwing an exception, you attempt to commit the transaction. If the commit succeeds, then you know the task entry has been written to the space, and you return a status of true. On the other hand, if the write throws an exception, you attempt to abort the transaction. If the abort succeeds, you know that the task entry was not written to the space (if it was written, it's discarded), and you return a status of false.
The third possibility is that an exception is thrown in the process of either committing or aborting the transaction. In this case, the outer catch clause prints a message, the transaction expires when its lease time is up, and the write operation doesn't occur, so you return a status of false.
Now that you have a new and improved writeTask method that tells you whether or not it has written a task into the space, you'll revamp the generateTasks method to make use of the new information. Here is a revised generateTasks that makes sure all the tasks get written into the space:
private void generateTasks() {
boolean written;
for (int i = 0; i < 10; i++) {
boolean written = false;
while (!written) {
written = writeTask(new AddTask(new Integer(i), new Integer(i)));
}
}
for (int i = 0; i < 10; i++) {
boolean written = false;
while (!written) {
written = writeTask(new MultTask(new Integer(i), new Integer(i)));
}
}
}
As you can see, the idea here is pretty simple. You wrap a loop around each call to writeTask and make the call repeatedly until it returns a status true to indicate that it successfully wrote the task into the space.
If you look back at the preceding original Master code, you'll notice that the takeResult method isn't particularly robust either, since you can't be sure whether or not the entry has been removed from the space. If the take returns a non-null value, then you know the entry has been removed from the space. But, if the take returns null, you can't be sure. For instance, if a RemoteException is thrown, the entry could have been removed from the space but then could have gotten lost before it made its way back to the client.
To make the takeResult method more fault tolerant, you'll follow the same scheme you used for writeTask. You'll wrap the take inside a transaction that's committed once you have the result entry in hand:
protected ResultEntry takeResult() {
// try to get a transaction with a 10-min lease time
Transaction txn = getTransaction(1000*10*60);
if (txn == null) {
throw new RuntimeException("Can't obtain a transaction");
}
ResultEntry template = new ResultEntry();
ResultEntry result;
try {
try {
result = (ResultEntry)
space.take(template, txn, Long.MAX_VALUE);
} catch (Exception e) {
txn.abort();
return null;
}
txn.commit();
return result;
} catch (Exception e) {
System.err.println("Transaction failed");
return null;
}
}
As you can see, takeResult either returns the result entry that was removed from the space or null if no result entry was removed.
You'll also need to revise the collectResults method to make use of the new and improved takeResult:
private void collectResults() {
ResultEntry result;
for (int i = 0; i < 20; i++) {
result = null;
while (result == null) {
result = takeResult();
}
System.out.println(result);
}
}
Here, each time through the outer loop, your goal is to retrieve one result entry from the space. In the inner loop, you call takeResult in an attempt to retrieve a result. If the method returns null (meaning it couldn't remove a result entry from the space), you iterate through the loop again; you'll continue looping until you manage to get a result from the space.
By now, you've managed to make your master and worker codes more robust and improved the compute server considerably. But that's not quite the end of the story. You may still have to contend with the compute server's scalability issues. Let's take a closer look.
Scaling the Compute Server Using Multiple Spaces
In one important respect, the compute server scales automatically as new resources become available: when new workers arrive on the scene, they pick up tasks and join in the computation, and the compute engine becomes faster and more powerful. But, in another respect, the compute server may face a serious scalability problem.
The compute engine employs just a single JavaSpace, and all interaction among master and worker processes occurs in the form of task and result entries exchanged through that one space. The reference implementation of JavaSpaces currently runs in a single Java Virtual Machine (JVM) on a single CPU -- there is no support yet for spaces that are distributed over multiple machines. So, if you imagine the compute server growing to encompass legions of workers, many masters, and massive numbers of task and result entries, it's easy to see that the use of a single JavaSpace running in a single JVM could pose a potentially serious bottleneck -- network traffic could pose a problem, as could storage limitations of the space.
What can you do about this threat to true scalability? You could, of course, sit back and wait for a JavaSpaces implementation to come along that runs across multiple JVMs. But, you don't have to wait: You can use the tools you already have at hand to build a compute server that makes use of multiple spaces and is thus more truly scalable than the single-space version.
In this design, the revamped master code will use Jini to find all the available JavaSpace services. Given the set of spaces and a collection of tasks to write, the master needs to implement a strategy for distributing tasks over the spaces. The strategy could be sophisticated and dynamic, perhaps based on some runtime knowledge of the load on various spaces. But for now, the master will take the simple approach of mapping a task to a particular space based on some property; here you'll map tasks to spaces based on integer task IDs. The master will write a task to a specific space and then later retrieve the result of that task from the same space. In the meantime, worker processes also use Jini to keep track of available JavaSpace services, and they monitor spaces looking for work to do. Your workers will use a simple round-robin scheme in which they start with the first space in the set, take and compute a task from that space, then move on to the next space to look for a task there, and so on.
|
A compute server using multiple spaces (16 KB) |
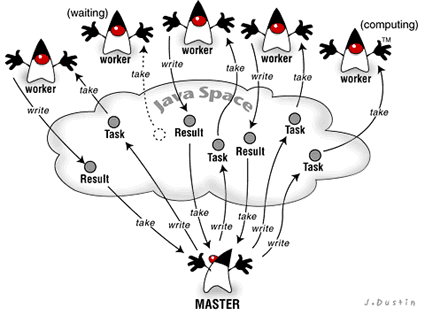
Let's take a look at some of the details. The new and improved compute server that makes use of multiple spaces is supplied in the javaworld.simplecompute3 package.
Gaining Access to Multiple Spaces
Both master and worker processes use Jini to find the set of JavaSpace services that are currently available. The processes will each make a call that looks like this:
ServiceMatches spaces = SpaceAccessor.getSpaces();
SpaceAccessor is a utility class that Eric Freeman and I created (which we've used in previous columns) that lets you gain access to spaces. We've added a new static getSpaces method to SpaceAccessor to find all currently available spaces. Without going into all the details of the getSpaces method, here is a peek at how it locates and returns JavaSpace services:
public static ServiceMatches getSpaces() {
. . .
Locator locator = new com.sun.jini.outrigger.DiscoveryLocator();
ServiceRegistrar lookupService = (ServiceRegistrar)locator.locate();
Class[] types = { JavaSpace.class };
ServiceTemplate template = new ServiceTemplate(null, types, null);
ServiceMatches matches = lookupService.lookup(template, 50);
return matches;
}
If you're unfamiliar with the mechanics and terminology of Jini lookup and discovery, you may want to make a detour to the Jini resources listed in Resources to get acquainted with them. In short, the preceding code first makes use of the DiscoveryLocator class's locate method to locate a Jini lookup service. Then it creates a ServiceTemplate, specifying that the template should match services of type JavaSpace. Next, the method passes the service template to the lookup service, which searches all of its registered services for matches and returns up to 50 of them (as was specified in the second argument to the lookup call). Finally, the getSpaces method returns the matches in the form of ServiceMatches, an object that will contain an array of matching ServiceItem objects, as well as a count of them. From each ServiceItem, you can retrieve the actual JavaSpace service and its service ID.
Master Maps Tasks to Spaces
The first thing the revamped Master code does is to make use of the getSpaces method to obtain access to the available spaces. Here's a sketch of the Master code, illustrating the ways in which it has changed:
public class Master {
private ServiceItem[] spaceServices;
private int numSpaces;
. . .
private void startComputing() {
ServiceMatches serviceMatches = SpaceAccessor.getSpaces();
spaceServices = serviceMatches.items;
numSpaces = serviceMatches.totalMatches;
. . .
generateTasks();
collectResults();
}
private void generateTasks() {
ServiceItem spaceService;
JavaSpace space;
boolean written;
Integer num;
for (int i = 0; i < 10; i++) {
spaceService = spaceServices[i % numSpaces];
space = (JavaSpace)spaceService.service;
num = new Integer(i);
written = false;
while (!written) {
written = writeTask(space, new AddTask(num, num));
}
written = false;
while (!written) {
written = writeTask(space, new MultTask(num, num));
}
}
private boolean writeTask(JavaSpace space, Command task) {
// write the task to the specified space
. . .
}
private void collectResults() {
ResultEntry result;
for (int i = 0; i < 10; i++) {
// try to retrieve two results, one for addition
// and one for multiplication
for (int j = 0; j < 2; j++) {
result = null;
while (result == null) {
result = takeResult(i);
}
}
}
}
protected ResultEntry takeResult(int i) {
. . .
ServiceItem spaceService = spaceServices[i % numSpaces];
JavaSpace space = (JavaSpace)spaceService.service;
ResultEntry template = new ResultEntry(i);
ResultEntry result;
// . . . within try/catch clauses:
result = (ResultEntry)space.take(template, txn, Long.MAX_VALUE);
}
After the call to getSpaces in startComputing, which returns a ServiceMatches result, you extract both the array of matching services and the count of how many there are from the result. Then you generate tasks and collect results, as described before.
The generateTasks method has changed a bit. Each time the method iterates through its loop, it determines which space to write the ith task to. Here the mapping is simple: the addition task i and multiplication task i are both written to the space (i % numSpaces) in the array of spaces. The writeTask method now takes a JavaSpace parameter, so it can write the task to the appropriate space.
The collectResults method has changed slightly too. It is now structured to have a nested loop and to remove addition results i and multiplication results i from the space. In fact, the takeResult method now takes an integer argument that is used to determine where to look for the result. To find the result of a task i, the method will look in the space (i % numSpaces) in the array of spaces, since that's where the task is written and where a worker writes the result.
Worker Interacts with Spaces, Round-Robin Style
Here is an outline of the code for the revamped Worker:
public class Worker {
private ServiceItem[] spaceServices;
private int numSpaces;
. . .
public Worker() {
ServiceMatches serviceMatches = SpaceAccessor.getSpaces();
spaceServices = serviceMatches.items;
numSpaces = serviceMatches.totalMatches;
. . .
}
public void startWork() {
ServiceItem spaceService;
JavaSpace space;
for (int i=0; ; i++) {
spaceService = spaceServices[i % numSpaces];
space = (JavaSpace)spaceService.service;
// . . . take task from that space, execute, write
// . . . result to that space
}
}
}
Like the revised master, the worker makes a call to getSpaces to obtain an array of available JavaSpace services. Armed with that, the worker loops indefinitely. At each iteration i, the worker concentrates its efforts on the space (i % numSpaces) in the array of spaces: It takes any task from that space, computes it, and returns the result to that space. In effect, the worker visits the spaces in round-robin fashion, taking and performing a task from each in turn.
To try out the new compute server, start up more than one JavaSpace service (if you're unsure how to do this, refer to "The Nuts and Bolts of Compiling and Running JavaSpaces Programs" listed in Resources). Then run a master process and one or more worker processes. From the output, you should be able to get a sense of how the master distributes tasks and how each worker visits the spaces in a round-robin way.
Conclusion
There you have it -- the making of a robust, scalable, and powerful compute engine. You learned about Jini transactions previously and how they provide a general and powerful model for building robust distributed applications. In this article, you've seen how to incorporate transactions into a fairly sophisticated application so that it will operate in a safe and correct manner in the presence of partial failure. You've also seen one way an application might make use of multiple spaces in order to become more truly scalable. With this information in hand, you should be well equipped to build your own applications that are fault tolerant and scalable.
Resources
- The complete source code for this example can be downloaded from:
http://www.javaworld.com/jw-06-2000/jiniology/code.zip
- For a more in-depth exploration of space-based programming concepts and code examples, as well as a detailed look at the JavaSpaces technology APIs, refer to Sun's official Jini Technology Series book on the topic: JavaSpaces Principles, Patterns, and Practice, Eric Freeman, Susanne Hupfer, and Ken Arnold (Addison-Wesley, 1999):
http://www.amazon.com/exec/obidos/ASIN/0201309556/
- You may wish to experiment with the code from JavaSpaces Principles, Patterns, and Practice, which is downloadable from Sun's Website:
http://java.sun.com/docs/books/jini/
- For information about getting your JavaSpaces (or Jini) programs up and running, refer to "The Nuts and Bolts of Compiling and Running JavaSpaces Programs" by Susanne Hupfer (Java Developer Connection, January 2000):
http://developer.java.sun.com/developer/technicalArticles/Programming/javaspaces/
- For specifics on Jini transactions, see The Jini Specification -- another Jini Technology Series book -- by Ken Arnold, Bryan O'Sullivan, Robert W. Scheifler, Jim Waldo, and Ann Wollrath (Addison-Wesley, 1999):
http://www.amazon.com/exec/obidos/ASIN/0201616343/
- You'll also find more information on Jini transactions in Core Jini by W. Keith Edwards (Prentice-Hall, 1999). This book provides in-depth treatment of Jini, including information about lookup and discovery:
http://www.amazon.com/exec/obidos/ASIN/013014469X/
- Read the whole "Make Room for JavaSpaces" series:
- Part 1. Ease the development of distributed apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js1.html
- Part 2. Build a compute server with JavaSpaces:
http://www.artima.com/jini/jiniology/js2.html
- Part 3. Coordinate your Jini apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js3.html
- Part 4. Explore Jini transactions with JavaSpaces:
http://www.artima.com/jini/jiniology/js4.html
- Part 5. Make your compute server robust and scalable:
http://www.artima.com/jini/jiniology/js5.html
- Part 6. Build and use distributed data structures in your JavaSpaces programs:
http://www.artima.com/jini/jiniology/js6.html
- Part 1. Ease the development of distributed apps with JavaSpaces:
- For more on using Jini's lookup service, see Bill Venner's "Locate services with the Jini lookup service" (JavaWorld, February 2000):
http://www.javaworld.com/javaworld/jw-02-2000/jw-02-jiniology.html
You'll also be able to find this information in the Jini, JavaSpaces, and Core Jini books (mentioned before). - Whether you wish to share information with other developers (including the Sun engineers that developed the Jini and JavaSpaces technologies), or to seek troubleshooting advice, the official JavaSpaces-users mailing list is the place to go:
http://archives.java.sun.com/archives/javaspaces-users.html
- The Jini-users mailing list also has a considerable amount of JavaSpaces-related discussion:
http://archives.java.sun.com/archives/jini-users.html
- For pointers to the JavaSpaces FAQ and other documentation, refer to the Sun Microsystems JavaSpaces page:
http://java.sun.com/products/javaspaces/
"Make Room for JavaSpaces, Part V" by Susan Hupfer was originally published by JavaWorld (www.javaworld.com), copyright IDG, June 2000. Reprinted with permission.
http://www.javaworld.com/jw-06-2000/jw-0623-jiniology.html
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
Dr. Susanne Hupfer is director of product development for Mirror Worlds Technologies, a Java- and Jini-based software applications company, and a research affiliate in the Department of Computer Science at Yale University, where she completed her PhD in space-based systems and distributed computing. Previously, she taught Java network programming as an assistant professor of computer science at Trinity College. Susanne coauthored the Sun Microsystems book JavaSpaces Principles, Patterns, and Practice.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)