
Simplify the Installation and Configuration of Jini Applications
First published in JavaWorld, January 2001
Sir Thomas More, the English philosopher, published a book in 1516 about an imaginary island. Inhabitants of this distant land lived the most ideal life imaginable: the citizens were educated, work was not overbearing and could still provide for a good living, society and government were just, and equality and peace ruled. He named this island Utopia.
If Sir Thomas were to write in the present day, he surely would consider an ideal computing landscape for his island as well. We can also surmise that he would seldom mention software installation, version upgrades, or system configuration. Fortunately, we do not have to imagine a utopian world without these chores, because we can take advantage of technologies like Java, Jini, and code mobility to create a more ideal computing environment here and now.
Alan Cooper, inventor of Visual Basic, mentioned in an online ITworld.com interview (see Resources) that the complexity of software installation and the capabilities of software are typically inversely proportional: the more capable a software package, the more difficult its installation. Anyone who has ever set up an operating system or database-management system would instantly agree with Cooper.
An important Jini promise is to disrupt this trend. As Jini architect Jim Waldo put it: "I dream of a world in which my children will never have to use InstallShield." In a recent JavaWorld interview (see Resources), Waldo referred to Java's ability to download code and objects on an as-needed basis from anywhere on the network.
Jini turns this capability into a practical benefit, providing a simple mechanism to locate objects on the network based on their functionality and download them to a client. Once a client obtains a reference to an object, it can use that reference to benefit from the object's functionality -- by calling methods on it, for instance. Anything that can be represented by a Java object (which includes practically any device or legacy code as well as Java programs) on the network can participate in a federation of such objects -- or services, as they are called in the Jini world.
To effectively use mobile objects, you must gain an understanding of how objects are located on the network, how they are loaded into a running application and participate in the application's execution, and the techniques used to make the object's class files available for downloading.
A Class Loader Refresher
The Java Virtual Machine's (JVM) job is to execute Java bytecode. Bytecode is stored in Java classfiles, which are loaded into the JVM via a class loader. Loading a class means locating a classfile that contains the desired type, based on the type's name, and then creating the class from that file (see the Java Virtual Machine Specification, Chapter 5). Once a class is loaded into a VM, it is linked into the VM's execution state, which means that it becomes part of the program's execution. Finally, the VM initializes the class by calling a special initialization method, which essentially corresponds to static initialization of the class.
When a JVM starts up, it loads a class using a bootstrap class loader. This first class must have a public static void main(String[] argv) method. The VM calls that method after initializing the class, and then starts executing code specified in the main() method.
Code in the main method will reference classes not yet loaded into the VM. When the VM encounters such a reference, it asks its class loader to load, link, and initialize this class as well. The class loader uses a codebase to try to locate the requested classfile. The codebase is the location where the class loader searches for classfiles.
If there were only a bootstrap class loader, this process would not be very powerful, since all classes would have to be installed at a predetermined location. Fortunately, the JVM's class loader architecture is modular. In addition to its built-in class loader, a VM allows any number of user-defined class loaders.
Since the second version of the JVM specification (available since Java 1.2), class loaders have formed a hierarchical relationship. Every class loader has a parent class loader. The bootstrap class loader is the the root node of the tree; the VM supplies it. When a class references a type not yet loaded into the VM, it first asks its class loader's parent to load it. This parent class loader, in turn, will delegate the class loading to its parent, and so forth, until the delegation reaches the ultimate parent, typically the bootstrap class loader. If the bootstrap class loader can find the class, it will load and create it, and pass a reference to that class back to its child class loader, which in turn will pass it back to its child, and so on, all the way to the class loader that requested the class. If the bootstrap class loader cannot locate the class, it will ask its child to locate it. If that child cannot load it, it will, in turn, ask its child. Only when none of its parents are able to return a reference to a loaded class will the original class loader try to load the class. If, at that point, the class is still not found, a ClassNotFoundException is thrown. This is the parent-delegation principle of class loading, which was first introduced in the 1.2 version of the JVM. (See Java Virtual Machine Specification, Section 5.3.2.)
In Java 2, the bootstrap class loader considers a CLASSPATH environment variable to determine its codebase. By default, the Java Core class library, supplied by the Java Runtime Environment (JRE), is also a part of that codebase. A different class loader, the Extension class loader, loads classes that are part of the Java Standard Extensions. Every other class is loaded by some other, user-defined, class loader.
|
Figure 1. The JVM's hierarchical class loader architecture |
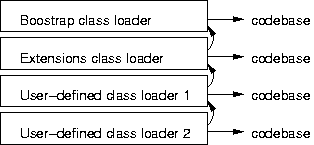
User-defined class loaders are specified in the Java programming language, and are created with code such as the following:
ClassLoader myClassLoader = new MyClassLoader(parentClassLoader);
Here parentClassLoader is a reference to a parent class loader instance. If a null is passed into the constructor, the bootstrap class loader will be the parent.
Here's an important method that the ClassLoader class specifies:
Class findClass(String className) {...}
Overriding this method can customize the way the specified class is located by the VM. If the class cannot be found, the VM throws a ClassNotFoundException. This method is typically called automatically by a ClassLoader's method:
Class loadClass(String className)
loadClass() does the following:
- It calls
findLoadedClass(className), which tells it if the specified class has already been loaded - It calls
loadClass(className)on the parent class loader, and, ultimately, on the bootstrap class loader - It calls
findClass(className)
It's important to remember that, based on the parent-delegation principle, the search for the class is ultimately delegated to the bootstrap class loader first, and then proceeds down the succession of child class loaders. If any class loader in this chain finds the classfile in its codebase, the VM will load, link, and initialize that class, and will not search any further.
The Benefits of Object Serialization
The JVM is able not only to load classes, but also to load objects (instances of classes) from the network via the Java object serialization mechanism (see the Java Object Serialization Specification for more details). Object serialization stores an object in a stream (i.e., in serialized form) in such a way that a Java program can reconstruct the object's state at a later time. You can save the binary stream representing the serialized object on stable storage, such as in a file or in a database management system, or send it over a wire.
For an object to be serialized, it has to implement either the java.io.Serializable or java.io.Externalizable interfaces, the latter being a subtype of Serializable. Serializable is a marker interface: it specifies no methods and merely indicates an object that has serializable state. All subclasses of a Serializable class are also serializable.
If instances of a class need a special way to serialize their state, that class can implement the Externalizable interface, which mandates two methods:
void readExternal(ObjectInput inputStream);
void writeExternal(ObjectOutput outputStream);
The main difference between Externalizable and Serializable is that the latter serializes, by default, the entire object graph, including states of an object's superclass. Externalizable gives you complete control over the serialization process.
If a supertype of a Serializable object is not itself serializable, then the object can assume the responsibility for saving and reconstructing the supertype's state (public, protected, and package fields if they share a package). For this to work, the superclass must have a public no-arg constructor. Further, if an object at runtime refers to a nonserializable object, the serialization system will throw a NotSerializableException, since it cannot write the complete object graph to the serialized stream.
Not all objects are suitable for serialization. Threads, for instance, do not have state that can later be recreated. (Actually, it is possible, but very difficult, to do so.) There can also be objects that should not be serialized for semantic reasons. Even if an object is serializable, you may not need to write all object fields to the stream during serialization. For instance, a variable that loses its meaning in a different execution context (such as something indicating the current time) should be marked transient, and will instead be initialized to its default value when reading it from the stream.
If an object holds multiple references to another object, this second object is serialized only once, and subsequent references to it will include a handle as a reference instead.
Along with instance data, the object serialization system writes a special object to the stream to represent the serializable object's class. This object is of the type java.io.ObjectStreamClass, and is essentially a descriptor for the Class object associated with the serializable object. It contains the class's name, its unique version number (serialVersionUID), and the class fields. In addition, it also has methods to obtain the actual class represented by this object, if, and only if, this class is already present in the local VM:
Class forClass();
If there is no class identified in the local VM that corresponds to this ObjectStreamClass, then a null value is returned.
|
Figure 2. An object graph written to a serialized stream |
Codebase Annotation
At this point, you have two sides of a story. On the one hand, the JVM's class loaders can find and load a class from their codebases, if they are given that class's name. On the other hand, you've seen that objects can be written to a stream and transported across VMs, and that object streams contain instance data to recreate the object as well as a descriptor of the object's class.
A complete story would need to connect these two sides. Given a class's name from the descriptor found in the serialized stream, the VM still needs to know where it should load the actual class from. Once it has that information, the VM can create a class loader with the codebase pointing to that location, load the class, link it to the current execution environment, and initialize its class data (i.e., set its static fields). Finally, the VM could use the data contained in the serialized object stream to create an instance of the class and initialize the object's instance data.
One solution would be to save the entire Class object corresponding to the serializable object's class instead of saving just a descriptor. However, that solution has two major downsides.
First, it would add significant overhead to each serial object stream. Because serialization means writing to the object stream, possibly transporting the object stream through a network, and then reading the stream, all these would take longer and would require more resources to perform with this overhead.
The second downside has to do with class evolution. Serializing an object means that it can survive the VM instance that created it, which implies that it is stored persistently across VM instances for longer periods of time. In this way, serialized objects are a persistent storage mechanism.
In practice, Java classes evolve over time: new fields might be added, methods may be implemented anew, bugs are discovered and fixed, and so on. With each of these changes, the class is altered. It would be unfortunate if you could not use information stored in serialized versions of an object with newer class versions. Good programming practice dictates that classes evolve in such a way that they preserve compatibility with older versions (i.e., that they be backwards compatible). Decoupling serialized objects from their corresponding Class objects allows for backwards-compatible class evolution, since newer class versions can still load serialized instance data from objects defined originally with an older version.
A better solution would be to tell the VM where it can download the object's class from. One way to do this is to stamp the code location for the class onto the serialized object stream -- in other words, to annotate the serialized object with the codebase URL. This method facilitates dynamic code mobility, because the VM can decide at runtime where it should download the classes from. This is also the fundamental technique used by Java RMI (see the Java Remote Method Invocation Specification, Chapter 10.3.1).
|
Figure 3. Codebase annotation on the serialized object stream |
The RMI runtime mechanism provides a special output stream, which, in addition to serializing the object, does the following:
- It annotates the location of the object's class to the serialized stream.
- When the object to be serialized is a remote object (i.e., when it implements
java.rmi.Remote), instead of serializing the object itself, its stub is serialized.
The codebase is specified with the following property to the VM:
-Djava.rmi.server.codebase=CODEBASEURL
The codebase property is a space-separated list of URLs. When deserializing an RMI stub annotated with the codebase, the RMI runtime will create a class loader for each codebase URL specified in this list. (The class java.rmi.RMIClassLoader is a factory of class loaders that facilitates this process.)
Jini services that use RMI to communicate between the service object and the service typically register their stubs in lookup services. (Recall that the RMI runtime replaces the object with its stub in the serialized stream.) This ensures that the RMI runtime annotates the serialized stub with the codebase for class downloading, and that this information will be available to clients of the service. The clients will use these URLs to download needed classfiles. The ability to download code is a key RMI feature. Jini builds on RMI's semantics of mobile code (see the Jini Architecture Specification, Section AR2.1.3).
The Role of MarshalledObject
The semantics of annotated codebases is useful even outside the RMI runtime environment -- in other words, for objects that are not transferred from one JVM to another in the context of an RMI call. In a dynamic environment, when objects are transferred from one JVM to another, you will likely need to transfer the required classes for these objects as well. Since they do not benefit from codebase annotations of the RMI runtime, they need to offer codebase information to client JVMs in a different way.
The java.rmi.MarshalledObject class is used for that purpose (see the Java Remote Method Invocation Specification, Section 7.4.9). Creating a MarshalledObject instance involves passing a serializable object to its constructor. MarshalledObject uses the special output stream of the RMI system that obtains the codebase property specified for the running VM, and saves this information along with the original object's serialized form. MarshalledObject's get() method returns the original object by downloading the needed classfile and reconstructing the object's state. Comparing two MarshalledObject instances produces equality if the two refer to the same object, regardless of the codebases specified.
When a service registers with a lookup service, it provides a ServiceItem to the lookup service's registrar. The service item contains the service ID, the service object, and a set of attributes associated with the service.
Each ServiceItem can hold an array of Entry objects. Each Entry specifies a set of attributes. Each attribute must be declared with reference types (no primitives allowed), and must be serializable objects. When an Entry is serialized, each field it declares is serialized separately as a MarshalledObject (see the Jini Core Platform Specification, Section EN.1.3). This also facilitates code mobility: when a client retrieves the service item with a lookup operation, it can reconstruct each Entry object.
Setting your Codebase Right
The key to making code mobility work in Jini is to specify the correct service codebase, and then to make sure that you can actually download the classfiles needed from these specified locations. Specifically, you need to cause the correct codebase to be annotated by the runtime system in serialized objects inside ServiceItems before a service registers with lookup services.
The easiest way to achieve this is to run one or more HTTP servers for each service, and then to specify the URLs to these servers to the VM that runs the Jini service. For example, if code is located on a machine named classserver in directory /export/home/classes_for_my_service, and the HTTP server is running on that machine's port 8080 with its root directory pointing to /export/home, you would specify the following property (note the trailing slash at the end of the line):
-Djava.rmi.server.codebase=http://classserver:8080/classes_for_my_service/
That property will cause the VM running the service to use the URL for codebase annotations of objects passed via RMI calls, or as MarshalledObjects. When the service registers with lookup services, the service object and the Entry for the service will point to the appropriate location. Recall that class loaders form a hierarchy, and that the VM first asks the bootstrap class loader for the class, then asks each class loader in the order of their hierarchy until one of them loads the requested class.
Therefore, the classfiles that the client downloads should not be available in the codebase of the client VM's bootstrap class loader, some other class loader that is ahead in the RMIClassloader hierarchy, or the class loader intended to load classes over the network. If the requested class can be loaded from local codebases, then code mobility will be circumvented. Therefore, you should not place classes that need to be downloaded in the CLASSPATH.
Developers new to Jini often encounter a situation in which their services work during development on the local machine, but stop working when they are deployed in a distributed environment. Most likely, during development, the classes were loaded locally all along, while at deployment these classes are no longer available at the remote client.
|
Figure 4. Deploying a Jini service |
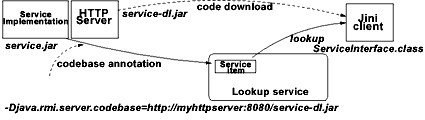
In Figure 4, the downloadable code needed by clients is placed in a special dl jar file, which is served by an HTTP server. The URL to this downloadable jar file is the codebase property for the service's VM.
Deploying a Jini Service
To make this discussion concrete, imagine a situation in which you just created what you think is an extremely useful Jini service. Since you just created the service, no one else has any code available to run it. In fact, at this point, no one even knows your service exists. Your goal is to make this service as widely available as possible to other Jini services or to human users.
Your first step is to start up your service. Alternatively, you can make the service available as an activatable RMI implementation (see the Java Remote Method Invocation Specification, Section 7). If your service is written in Java (it does not have to be), the classfiles needed to run the application must be available to the local VM. There is nothing special here, since this is true of any Java program: the VM will start executing a main() method somewhere, and will load and link classes as it needs them via its class loaders. The best way to make these classes available is to include them in a jar file, and then ensure that this jar file is available to a class loader on the local VM. In other words, it has to be in the classpath for the local VM. (A convenient way is to set this jar file up as an executable jar.) No object mobility is involved at this point.
Next, you need to ensure that clients can obtain the necessary code to interact with your service. If you implemented your service using RMI, then the proxy object representing your service in the lookup service will likely be the RMI stub. Recall that when a stub is serialized via the RMI runtime, the codebase from which its classes can be downloaded is annotated in the object stream. As I discussed earlier, this codebase is obtained by the RMI system from the running VM's java.rmi.server.codebase property.
There are three steps necessary to make classfiles available to clients:
- Consider the classes the client needs to interact with your service, and create a separate jar file from these classes. By convention, this jar file is named
servicename-dl.jar, wheredlstands for downloadable (substitute the name of your own service forservicename). Every Jini service in the JSK is organized in this way. For instance, the lookup service implementation in the JSK consists of two files:reggie.jarandreggie-dl.jar. Any class that the client might need to load but does not have (because it is not part of the JDK version you're using) must be in thedlfile, including any exception classes specified by your service object. You can put any net.jini classes the proxy depends on in thedlfile as well. - Make available some mechanism for clients to download the
dlfile. The easiest way is to run an HTTP server and place thedljar file in a directory served by that server. Alternatively, you can put thedlfile on an FTP server, or a shared filesystem. However, HTTP is by far the easiest way to make code downloading work. Using file URLs is usually a very bad idea, because the file systems they refer to will not likely be available to Jini clients. The JSK includes a simple HTTP server suitable for this purpose. You can run this server with the command:
java -jar MY_JINI_DIRECTORY/lib/tools.jar -port PORT_NUMBER -dir SERVER_ROOT_DIRAn additional
-verboseparameter will also print out each download request. - When starting up the service, specify the URL to the
dlfile as thejava.rmi.server.codebaseproperty. Thus, to start up your service, you might use a command line like this:
java -cp LOCALLY_NEEDED_CLASSES/myservice.jar \
-Djava.rmi.server.codebase=http://myhttpserver:8080/myservice-dl.jar \
-Djava.security.policy=my_security_file \
... [OTHER PARAMETERS] ...
myservice_main_classFor an activatable service, the codebase information needs to be available to the VM for the activation group that runs the service (see "Activatable Jini Services").
You are ready to register your service with lookup services:
- Create a
ServiceItemobject to represent the service in the lookup service. Your service objects, along withEntryobjects in the service's attribute set, will be annotated with thecodebasevalue specified to the VM (see above). Thus, when clients obtain the service item, they will be able to download the needed code from that location. - Discover a lookup service and obtain its
ServiceRegistrarobject. - Pass the service item to the registrar's
register(ServiceItem serviceItem, long leaseDuration)method, thereby obtaining theServiceRegistrationobject corresponding to this registration. You can use the registration object to renew your service's leases, and in general to maintain the relationship between your service and the lookup service.
Note that your service needs to load classes to interact with the lookup service. Now your service becomes a client of the lookup service and needs to download the necessary classes from the lookup service so it can instantiate the lookup service's proxy. Your service will download the reggie-dl.jar file from the lookup service's codebase. To be able to load and link these classes, your service needs to grant the required permissions to its VM. It is beyond the scope of this article to discuss how to configure security policy files to allow this. The JSK contains several example policy files in the /example directory.
To summarize, your service uses the following jar files:
myservice.jar(its own classfiles), in addition to any other package it might use. These need to be in the classpath of the service's local VM.jini-core.jarand possiblyjini-ext.jarto interact with the Jini environment (perform discovery, use leasing, participate in transactions, and so on.) Alternatively you could place the necessary classes inmyservice.jar.myservice-dl.jar, which consists of files the client will need to interact with the service. This jar file will be downloaded from a codebase specified by your service. This codebase must be specified with thejava.rmi.server.codebaseproperty to the service's VM.
The Client's View
You are now ready to take up the client's view. This article's premise is that code mobility reduces installation and configuration of otherwise complex applications in a Jini environment. Jini clients discover services in a Jini federation based on three possible attributes: the service's unique service ID, the service's programming language type, and any attributes the service may register as Entrys in the lookup service (see the Jini Core Platform Specification, Section DJ.2).
The most important of these is the programming language type. Since the client is another Java program (or a non-Java program that knows how to call methods on a Java object), it needs to know something about the contract the service interface specifies between the client and the server. This contract is expressed in terms of both Java code and that code's semantic definition -- neither of these would suffice alone. You might have a Java interface with this definition:
public interface Bank {
/**
* Deposit the specified amount of money to the specified account.
* If the specified account does not exist, throw NoSuchAccountException.
*/
public void deposit(int amount, BankAccount acct, Transaction txt)
throws RemoteException, NoSuchAccountException, TransactionException;
/**
* Withdraw the specified amount from the specified account. If
* the account does not exist, throw NoSuchAccountException. If
* the balance on the account is less than the amount to be
* withdrawn, throw InsufficientFundsException.
*/
public void withdraw(int amount, BankAccount acct, Transaction txt)
throws RemoteException, NoSuchAccountException,
InsufficientFundsException, TransactionException;
}
A programmer creating an ATM machine's software, for instance, could use this interface between the machine and the bank's account database. The programming language describes syntax, while the human language specification describes the semantics. (See Object-Oriented Software Construction, Bertrand Meyer and "An interview with James Gosling"). The ATM machine's programmer must be familiar with both to effectively use the service. For instance, she needs to consider how to handle the various exception conditions, know what to do if the customer has more than one account, and so forth.
Therefore, Jini encourages the use of well-known service APIs. The idea is that banks, for instance, could get together and agree on the contract that bank account databases would need to guarantee, essentially defining what it means to be a bank account. The Jini Community Process fosters this type of collaboration (see Jini Community Pattern Language). For example, the major printer manufacturers have worked out a Jini Printing API. Printer vendors can independently implement this API, essentially guaranteeing the API-specified contracts in their products. There are similar efforts under way in the automotive, tourism, and insurance industries. Once a service API is defined, the source code and the documentation is available to any implementer, as well as to clients needing the promised functionality.
The consequence of this approach is that the service interface, in the Bank object example, will be available locally to both the client and the service: it is a contract on which both agree. Therefore, the ATM machine can request lookup services to return objects that implement this interface, and it can be certain that any implementation guarantees the contract specified by the interface.
What the ATM machine's programmer does not have to worry about are three things: first, how the service is implemented (i.e., what actually takes place to deposit and withdraw money from the account); second, how the service proxy communicates with the service implementation, since this is a private matter of the service; and third, how the ATM will obtain code for the parameters and return types when calling methods on the service, such as the BankAccount class, or the exception classes defined by the service.
In addition to the classfile of the service type, the client also needs to have the jini-core.jar file available locally. Both are necessary to initiate the discovery protocol. (For more on discovery, see the Jini Platform Specification, Section DJ2).
What if the client does not know the code for a service API? There is no magic here, and any solution to this problem will likely produce incorrect, and unpredictable, results (see JavaWorld's interview with Jim Waldo). If a human user is looking for a service, and the service provides a serviceUI, then the user could conceivably search a description of the service and obtain a user interface to clarify his choice. For instance, searching for "bank API," a user could be presented with a menu of all available services that have to do with banks or banking. At that point, if the user recognizes a desired service (from a longer description, for instance), he could select and interact with it via its serviceUI. If another piece of software, rather than a person, is looking for a service, you would need much more complex solutions for this type of ad hoc discovery, likely employing some form of heuristics, or other artificial intelligence techniques.
If your service is not implementing a well-known service API, you need one additional step after you register your service and make downloadable code available to clients: you need to publish your interface definition so that client implementers can easily access it. This is another benefit of the Jini Community Website, where anyone can place publicly available code and documentation to define a new service. If the service is of a general nature, you can create a Jini project, which facilitates communication with others using the service.
Summary
Object mobility on the network is the cornerstone of Jini technology, and one of the most powerful ways in which Jini is able to contribute to a more robust, less error-prone computing environment. Jini exploits the JVM's ability to dynamically download and link code from anywhere on the network, and takes advantage of object serialization to transport objects between Java VMs in a distributed Jini federation. To allow both objects and classfiles to independently traverse the network, Jini builds on the codebase annotation technology employed by Java RMI: the codebase URLs for an object's class are annotated to the object's serialized stream. These techniques together allow a client to have only a well-known Java language interface type locally available. The Jini discovery protocols can find lookup services and retrieve any object that guarantees the contract specified by the service interface. Classes required to interact with the service are then dynamically downloaded to the client from the service's codebase URLs.
As for the island of Utopia? Sir Thomas More was imprisoned and executed by Henry VIII in 1532, so he unfortunately won't be able to report on a utopian computing landscape. However, he would certainly see the promise that Jini and mobile code can bring to a more ideal computing world.
Resources
- Allen Holub talks with Alan Cooper in ITworld.com's Interviews forum:
http://www.itworld.com/jump/jw-0105-jiniology/forums.itworld.com/webx?7@@.ee6cff8/2!skip=-22
- The Java Virtual Machine Specification, Second Edition, Chapter 5:
http://java.sun.com/docs/books/vmspec/2nd-edition/html/ConstantPool.doc.html
- The Java Object Serialization Specification:
http://java.sun.com/j2se/1.3/docs/guide/serialization/spec/serialTOC.doc.html
- The Java Remote Method Invocation Specification:
http://java.sun.com/j2se/1.3/docs/guide/rmi/spec/rmiTOC.html
- Section 10.3.1 describes codebase annotation:
http://java.sun.com/j2se/1.3/docs/guide/rmi/spec/rmi-protocol4.html
- Section 3.4 describes dynamic class loading:
http://java.sun.com/j2se/1.3/docs/guide/rmi/spec/rmi-arch5.html
- Section 7.4.9 describes the
MarshalledObjectclass:
http://java.sun.com/j2se/1.3/docs/guide/rmi/spec/rmi-activation5.html
- Section 7 describes activatable RMI objects:
http://java.sun.com/j2se/1.3/docs/guide/rmi/spec/rmi-activation.html
- The Jini Architecture Specification, Version 1.1:
http://www.sun.com/jini/specs/jini1.1html/jini-title.html
- Jini Technology Glossary:
http://www.sun.com/jini/specs/jini1.1html/glossary-title.html
- The Jini Core Platform Specification:
http://www.sun.com/jini/specs/jini1.1html/core-title.html
- The Jini Core Platform Specification, Section DJ2, explains discovery:
http://www.sun.com/jini/specs/jini1.1html/discovery-spec.html#19702
- "Activatable Jini Services", Frank Sommers (JavaWorld, September 15, 2000):
http://www.javaworld.com/javaworld/jw-09-2000/jw-0915-jinirmi.html
- Gosling speaks about the important of knowing the semantic contract specified by a Java object in "An Interview with James Gosling," Bill Venners (JavaWorld, June 6, 2000):
http://www.javaworld.com/javaworld/jw-06-2000/jw-0608-gosling.html
- "Jini Community Pattern Language" Richard P. Gabriel and Ron Goldman:
http://jini.org/JiniCommunityPL.html
- "Sun Lets Jini Starter Kit 1.1 Out of the Bottle" (JavaWorld, December 8, 2000) -- Jini architect Jim Waldo talks to Frank Sommers about the importance of having the Java service interface available to both client and service:
http://www.javaworld.com/javaworld/jw-12-2000/jw-1208-waldo.html
- The Jini ServiceUI project home page:
http://developer.jini.org/exchange/projects/serviceui
- Object-Oriented Software Construction, Second Edition, Bertrand Meyer (Prentice Hall, March 2000):
http://www.amazon.com/exec/obidos/ASIN/0136291554/o/qid=978025334/sr=2-1/104-2016221-1893530
- An electronic edition of Thomas More's Utopia:
http://www.d-holliday.com/tmore/utopia.htm
- The Jini Printing working group homepage contains the printing APIs:
http://developer.jini.org/exchange/users/jpgwg/
- "Dynamic Code Downloading Using RMI" -- an excellent short tutorial at the RMI homepage:
http://java.sun.com/j2se/1.3/docs/guide/rmi/codebase.html
- Specifying the codebase requires the use of URLs. To learn about properly constructing URLs, see RFC 1738:
http://www.rfc-editor.org/rfc/rfc1738.txt
- In addition, RFC 1808 describes the use of relative URLs:
http://www.rfc-editor.org/rfc/rfc1808.txt
- Adrian Colley from Sun posted this message to the RMI mailing list on the use of URLs in codebase specifications:
http://archives.java.sun.com/cgi-bin/wa?A2=ind0009&L=rmi-users&O=A&P=23120
- Bill Venners's Under the Hood series provides a wealth of information on the internals of the Java Virtual Machine, including class loading:
http://www.artima.com/underthehood/index.html
- You can also purchase Venners's book on the same topic, Inside the Java Virtual Machine:
http://www.artima.com/insidejvm/blurb.html
- Complete listing of all previous Jiniology articles:
http://www.javaworld.com/javaworld/topicalindex/jw-ti-jiniology.html
- Sign up for the JavaWorld This Week free weekly email newsletter and keep up with what's new at JavaWorld:
http://www.idg.net/jw-subscribe
- Talk about Jini and other distributed Java services in JavaWorld's Java in the Enterprise discussion:
http://www.itworld.com/jump/jw-0105-jiniology/forums.itworld.com/webx?14@@.ee6b80a
"Object Mobility in the Jini Environment" by Frank Sommers was originally published by JavaWorld (www.javaworld.com), copyright IDG, January 2001. Reprinted with permission.
http://www.javaworld.com/javaworld/jw-01-2001/jw-0105-jiniology.html
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
-
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)