This post originated from an RSS feed registered with Java Buzz
by Thorben Janssen.
Original Post: Result Set Mapping: Complex Mappings
Feed Title: Thoughts on Java
Feed URL: http://www.thoughts-on-java.org/feeds/posts/default
Feed Description: Tutorials and howtos about Java and Java EE related topics.
This is the second part of my SQL result set mappings series. We had a look at some basic result type mappings in the first post Result Set Mapping: The Basics. In this one, we will define more complex mappings that can map a query result to multiple entities and handle additional columns that cannot be mapped to a specific entity.
Result Set Mapping: Constructor Result Mappings (coming soon)
Result Set Mapping: Hibernate specific features (coming soon)
The example
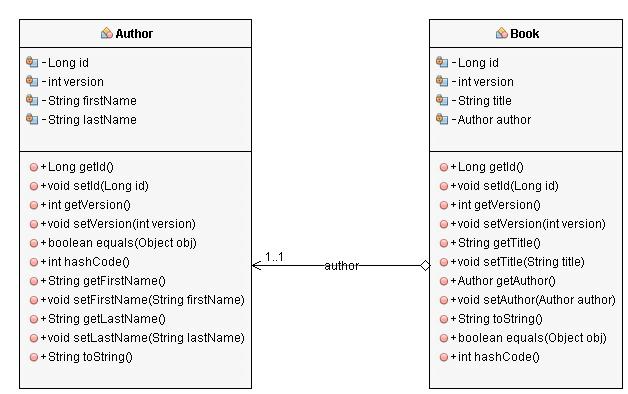
Before we dive into the more complex mappings, lets have a look at the entity model that we will use for the examples. We used the Author entity with an id, a version, a first name and a last name already in the first post of this series. For the more complex mappings, we need the additional Book entity which has an id, a version, a title and a reference to the Author. To keep it simple, each book is only written by one author.
I used Wildfly 8.2 with Hibernate 4.3.7 to test the examples in this series. But as these are standard JPA features, you should be able to use them with every JPA 2.1 implementation, like EclipseLink. You can find the source code on my github account.
How to map multiple entities
In real life applications we often select multiple entities with one query to avoid the additional queries that would be required to initialize lazy relations. If we do this with a native query or a stored procedure call, we get a List<Object[]> instead of entities. We then need to provide a custom mapping that tells the EntityManager to which entities the Object[] shall be mapped and how this is done.
In our example we could define a query that returns books and its author in one query.
SELECT b.id, b.title, b.author_id, b.version, a.id as authorId, a.firstName, a.lastName, a.version as authorVersion FROM Book b JOIN Author a ON b.author_id = a.id
As the Author and the Book table both have an id and a version column, we need to rename them in the SQL statement. I decided to rename the id and version column of the Author to authorId and authorVersion. The columns of the Book stay unchanged.
OK, so how do we define a SQL result set mapping that transforms the returned List of Object[] to a List of fully initialized Book and Author entities? The mapping definition looks similar to the custom mapping that we defined in the post about basic result set mappings. As in the previously discussed mapping, the @SqlResultMapping defines the name of the mapping that we will use to reference it later on. The main difference here is, that we provide two @EntityResult annotations, one for the Book and one for the Author entity. The @EntityResult looks again similar to the previous mapping and defines the entity class and a list of @FieldResult mappings.
If you don't like to add such a huge block of annotations to your entity, you can also define the mapping in an XML file. As described before, the default mapping file is called orm.xml and will be automatically used, if it is added to the META-INF directory of the jar file. The mapping definition itself looks similar to the already described annotation based mapping definition.
OK, that might not look like what we wanted to achieve in the first place. We wanted to get rid of these Object[]. If we have a more detailed look at the Objects in the array, we see that these are no longer the different columns of the query but the Book and Author entities. And as the EntityManager knows that these two entities are related to each other, the relation on the Book entity is already initialized.
List<Object[]> results = this.em.createNativeQuery("SELECT b.id, b.title, b.author_id, b.version, a.id as authorId, a.firstName, a.lastName, a.version as authorVersion FROM Book b JOIN Author a ON b.author_id = a.id", "BookAuthorMapping").getResultList();
results.stream().forEach((record) -> { Book book = (Book)record[0]; Author author = (Author)record[1]; // do something useful });
How to map additional columns
Another very handy feature is the mapping of additional columns in the query result. If we want to select all Authors and their number of Books, we can define the following query.
SELECT a.id, a.firstName, a.lastName, a.version, count(b.id) as bookCount FROM Book b JOIN Author a ON b.author_id = a.id GROUP BY a.id, a.firstName, a.lastName, a.version
So how do we map this query result to an Author entity and an additional Long value? That is quite simple, we just need to combine a mapping for the Author entity with an additional @ColumnResult definition. The mapping of the Author entity has to define the mapping of all columns, even if we do not change anything as in the example below. The @ColumnResult defines the name of the column that shall be mapped and can optionally specify the Java type to which it shall be converted. I used it to convert the BigInteger, that the query returns by default, to a Long.
List<Object[]> results = this.em.createNativeQuery("SELECT a.id, a.firstName, a.lastName, a.version, count(b.id) as bookCount FROM Book b JOIN Author a ON b.author_id = a.id GROUP BY a.id, a.firstName, a.lastName, a.version", "AuthorBookCountMapping").getResultList();
results.stream().forEach((record) -> { Author author = (Author)record[0]; Long bookCount = (Long)record[1]; System.out.println("Author: ID ["+author.getId()+"] firstName ["+author.getFirstName()+"] lastName ["+author.getLastName()+"] number of books ["+bookCount+"]"); });
This kind of mapping comes quite handy, if your query becomes complex and the result has no exact mapping to your entity model. Reasons for this can be additional attributes calculated by the database, as we did in the example above, or queries that select only some specific columns from related tables.
Conclusion
In the first post of this series, we had a look at some basic ways to map query results to entities. But this is often not sufficient for real world applications. Therefore we created some more complex mappings in this post that:
can map a query result to multiple entities by annotating multiple @EntityResult annotations and
can handle columns, that are not part of the entity, with the @ColumnResult annotation.
In the following posts, we will use the constructor result mapping, that was introduced in JPA 2.1 and have a look at some Hibernate specific features:
.png)