
Sir Thomas More's famous treatise, Utopia [1], recounts the experiences of a fictitious traveler to an imaginary island where everyone lives well, all citizens are educated, and no one is left behind. Penned in 1516, Utopia describes how government, professions, social relations, travel, the military, religion, and even marriage work in that "ideal" world.
If Sir Thomas were writing today, he would do well to include a chapter on data management in his book. In an ideal world, what would data management be like? While we can only fancy More's description, the Java Content Repository API (JSR 170) [2] expert group may have a partial answer. The new API, which was approved as a final Java standard by the JCP [3] on May 31st, claims to radically simplify Java data management by creating a unified access model for data repositories.
If the Java Content Repository (JCR) API expert group's vision bears out, in five or ten years' time we will all program to repositories, not databases, according to David Nuescheler, CTO of Day Software [4], and JSR 170 spec lead. Repositories are an outgrowth of many years of data management research, and are best understood as fancy object stores especially suited to today's applications.
To experience first hand whether the JCR API's promise of simplifying Java data management is real or utopian, I took the JSR 170 reference implementation, Apache Jackrabbit [5], on a test drive. I built a small blogging application with JCR, and will share my experiences with you in this article.
My findings? The JCR is worth a serious look if you are building real-world, data-centric Java applications. And while programming to a content repository as opposed to a database can save serious development time, the devil—as you've probably expected—is in the details.
Not your father's database
Commercial repositories are often implemented on top of more traditional database, and even filesystem, technology. Therefore, repositories often serve as a layer between a data store, such as an RDBMS, and an application requiring access to persistent data. A repository typically consists of the following components [6]:
- A repository engine that manages the repository's content, or repository objects.
- A repository information model that describes the repository contents.
- A repository API that allows applications to interact with the repository engine and provides for querying or altering the repository information model.
- Optionally, a repository includes an interface to a persistent store, or a persistence manager.
The relationships between these components are illustrated in figure 1.

What benefits do these components bring to a plain old database? According Microsoft Research's Phil Bernstein, who served as architect of that company's object repository that first shipped in Visual Basic 5, a repository engine offers six features above a traditional relational or object database management system [6]:
- Object management: Managing repository objects means storing a repository object's state. That state comprises the object's property and attribute values. Repositories typically allow applications to manage objects via the repository API.
- Dynamic extensibility: Each repository object has a type. The repository information model is a collection of the possible object types in the repository as well as of the objects that implement those types. The repository engine allows adding new types and extending existing types. In contrast to relational databases, a repository information model, including type information, is often implemented not as metadata, but as a collection of first-class repository objects. As a result, a repository often has no metadata in the sense of relational database metadata. This is roughly analogous to how objects run in a Java virtual machine, for instance: Type information is represented by first-class objects of the type
Class, and the JVM associates non-Classobjects withClassobjects that define the object's type. - Relationship management: While relational databases define entity relations between database objects, they do so at the level of the database schema (metadata), not in terms of actual database objects. By contrast, repositories allow object relationships to be specified in terms of first-class objects representing those relationships. For instance, two
Pageobjects might be related via aLinkobject, denoting that one page links to another. BecauseLinkis a repository object, it can be associated with a rich object type: For example, one describing a bi-directional link between the two pages. A repository engine enforces referential integrity between related objects. - Notification: Objects both inside and outside the repository may listen to changes occurring to repository objects. The repository engine dispatches notifications as such changes take place.
- Version management: Most applications today require versioned data: Given a data item, an application must be able to access the current as well as all past versions of that data item. Neither relational nor object databases provide standard, out-of-the-box versioning, leaving versioning chores to each application accessing the data store. By contrast, keeping track of versions, and making those versions available to applications, is an important repository feature.
- Configuration management: Applications often need to keep track of subsets of repository objects. For instance, a single repository might contain objects belonging to several users or companies, or might comprise objects for several software packages. Such repository object subsets are termed configurations or workspaces.
If your application can use any of the above features, then repositories might be for you. There are dozens of repository products to choose from. For starters, database vendors often ship a repository component as part of their high-end DMBS product (the Microsoft Repository ships with SQL Server, for instance) [7]. IDE and software configuration tool vendors also include repositories in their offerings. A version control system, such as CVS or Subversion, are specialized repositories [8]. In the near future, even file systems will incorporate some repository features, such as Sun's ZFS filesystem [9], and the WINFS filesystem that will ship with Microsoft's Longhorn operating system [10]. Many open source and commercial content management systems (CMS) are also based on repositories. And now, there is Jackrabbit, an open-source content repository from the Apache Incubator Project.
Enter Jackrabbit
Until the Java Content Repository API, content repository vendors each provided their own access protocols and APIs. The JCR API defines a vendor-neutral way to access repositories from Java, promising to deliver easy access to repositories from Java applications, much the same way JDBC defines a unified API for accessing relational databases.
The JCR API is unique not only in its ambitious goal, but also because it was one of the first JCP JSRs developed as an open-source project from its inception. The specifications, the reference implementation, and the Technology Compatibility Kit (TCK) are all licensed under an Apache-style license, thanks to the licensing flexibility of JCP 2.6 [11].
"We realized from the beginning that to have a credible [Java] standard, you have to have a credible open-source implementation," says Day Software's Nuescheler, who leads the expert group. "As far as I know, we're the first JSR [to] license this way from the beginning. We found the flexibility of JCP 2.6 very helpful."
"We didn't want just a dead reference implementation, and thought of ways to leverage the open-source licensing and the open source community spirit around the JSR," adds Nuescheler. "We looked for a vehicle for developing [the] reference implementation. Apache is one of best open-source brands you can get, and is one of the most credible infrastructure providers, especially in the Java world. So we started to move the reference implementation into the [Apache] incubator project."
The resulting Apache Jackrabbit project provides the codebase for the JCR API's reference implementation and TCK. "Beyond that, [Jackrabbit] is Apache's content repository tool," says Nuescheler.
The Jackrabbit code base contains not only the JCR API reference implementation, but also a fully functional repository as well as several contributed libraries for tasks, such as accessing a remote repository via RMI. There is even a JDBC persistence manager to allow plugging in a relational database as a persistent store, and an object-relational mapping tool that allows Hibernate applications to use the repository.
In addition to simply storing repository objects, Jackrabbit's repository integrates with Apache Lucene to allow finding repository objects via textual search. Additional retrieval methods are via SQL queries, or direct, path-based queries using XPATH. The Jackrabbit repository can be installed either in a J2EE container, or run as a standalone application.
The JCR information model
The JCR API defines a very simple hierarchical data model. That model consists of Workspaces, and each workspace can contain one or more Items. An Item is either a Node or a Property. While a Node can have child nodes, a Property cannot. Instead, a Property is a name-value pair that contains the "real" data items associated with a node. A workspace contains one root node. Workspace items are related in a hierarchical fashion, with properties being the leaves.
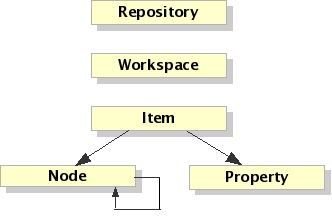
Each node is defined by a node type. A node's primary node type defines what names, properties, and child nodes a node may have. The set of node types in a repository is a major part of a repository's information model. Although not technically correct, intuitively, nodes are similar to classes. The portion of the information model that consists of node types is then analogous to the object model of an application (or even the schema of a database).
An interesting node type is the mixin type. While a node can have only one primary type, it can have any number of mixin types. Mixin types define additional properties for a node, and are somewhat similar to the ability of an object to implement multiple interfaces.
The Jackrabbit repository defines a handful of built-in node types. One of the more interesting built-in mixin types is mix:referenceable. A referencable node is one that exposes a Universally Unique Identifier (UUID) property, jcr:uuid, for the purpose of allowing the node to be referenced by that ID from other nodes. When automatically assigned to a referenceable node on creation, a UUID is unique within the workspace, across multiple workspaces, and even across multiple repositories. Referenceable nodes allow the Jackrabbit repository engine to enforce relationships between repository items.
Another mixin node type is mix:versionable. All versionable nodes are also referenceable, and it is through references that the repository keeps version histories. When a new version of a versionable node is saved, the repository automatically adds that new version to the node's version history. Thus, an application that uses Jackrabbit for data access need not implement versioning code.
Once a node is saved in a workspace, that node can be referenced either via the repository hierarchy or directly via the node's UUID. Thus, a JCR API can support both hierarchical repositories, such as those based on an object graph, and data models that do not lend themselves to hierarchical structures, such as those more akin to a relational model. In addition to direct referencing, Jackrabbit supports node discovery based on node type, as well as SQL and XPATH searches. Such searches return iterators over the search results that allow not only sequential access, but also support "skipping" ahead.
The default Jackrabbit repository is based on the file system. However, Jackrabbit provides a JDBC persistence manager that relegates data storage to a relational database. As any JCR-compliant repository, Jackrabbit can be accessed through any protocol such as WebDAV or RMI. Examples for different repository access modes are included in the Jackrabbit source distribution.
Blogging with Jackrabbit
To see for ourselves how the JCR API helps in real-world application development, I decided to implement a simple blog management app with Jackrabbit. We were especially interested to compare a content-repository approach with a Hibernate-based solution, since both methods claim to reduce application code complexity.
A blogging application's data model is simple: it typically consists of a set of blog entries, and each blog entry may refer to comments made about that entry. Each comment, in turn, may have zero or more further comments, entered as replies in the discussion thread.
Such a hierarchical data model is well-suited to a repository's tree structure. A coincidence? Perhaps, but many other enterprise tasks are also amenable to hierarchies, such as inventory tracking, user administration, and order management.
In a relational model, defining such a hierarchical structure involves creating self- referencing relations. In the JCR repository model, however, it merely requires defining a new node type, blogentry. That type might have a few properties, such as a title, an author, a date, and the blog's text. In addition, the blogentry type may have a set of attachments as well as comments. The attachments may be binary content, such as images or documents.
The following code snippet authenticates a user into a repository, retrieves the repository's root node (assuming the repository contains a single workplace), creates a new node representing a blog entry, and adds that entry into the repository's root node:
//A repository config file.
String configFile = "repotest/repository.xml";
//Filesystem for Jackrabbit repository
String repHomeDir = "repotest";
//Register the repository in JNDI
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"org.apache.jackrabbit.core.jndi.provider.DummyInitialContextFactory");
env.put(Context.PROVIDER_URL, "localhost");
InitialContext ctx = new InitialContext(env);
RegistryHelper.registerRepository(ctx,
"repo",
configFile,
repHomeDir,
true);
//Obtain the repository through a JNDI lookup
Repository r = (Repository)ctx.lookup("repo");
//Create a new repository session, after authenticating
Session session =
r.login(new SimpleCredentials("userid", "".toCharArray()), null);
//Obtain the root node
Node rn = session.getRootNode();
//Create and add a new blog node. The node's type will be "blog".
Node n = rn.addNode("blog");
n.setProperty("blogtitle",
new StringValue("Chasing Jackrabbit article"));
n.setProperty("blogauthor", new StringValue("Joe Blogger"));
n.setProperty("blogdate", new DateValue(Calendar.getInstance()));
n.setProperty("blogtext",
new StringValue("JCR is an interesting API to lo learn."));
session.save();
We can subsequently look up the nodes in the repository via any of the query mechanisms supported by a repository. JCR compliant repositories must support at least XPATH, but Jackrabbit also supports SQL. The following code snippet finds and lists all blog entries written by "Joe Blogger:"
Workspace ws = session.getWorkspace();
QueryManager qm = ws.getQueryManager();
//Specify a query using the XPATH query language
Query q =
qm.createQuery("//blog[@blogauthor = 'Joe Blogger']", Query.XPATH);
QueryResult res = q.execute();
//Obtain a node iterator
NodeIterator it = res.getNodes();
while (it.hasNext()) {
Node n = it.nextNode();
Property prop = n.getProperty("blogtitle");
System.out.println("Found blog entry with title: "
+ prop.getString());
}
Adding a comment to a blog entry involves finding the blog entry's node, and adding a child node representing the comment. The code is so simple, that we leave it as an exercise to the reader.
The following code example will instead demonstrate how to make a blog entry versionable. Versions can allow an application to let a user edit a blog entry before posting it, and to revert to previous versions, if needed. Making a node versionable requires adding the mix:versionable mixin type to the node:
Node n = rn.addNode("versionedblog");
n.addMixin("mix:versionable");
n.setProperty("blogtitle", new StringValue("Versioned rabbit") );
n.setProperty("blogauthor", new StringValue("Joe Blogger"));
n.setProperty("blogdate", new DateValue(Calendar.getInstance()));
n.setProperty("blogtext",
new StringValue("JCR is an interesting API to lo learn."));
session.save();
By adding the mixin node type mix:versionable to the node, a version history is created when invoking session.save(). Having saved an initial version, the blog entry can subsequently be retrieved, edited, and a new version saved:
Query q =
qm.createQuery("//versionedblog[
@blogauthor = 'Joe Blogger' and
@blogtitle = 'Versioned rabbit']", Query.XPATH);
QueryResult res = q.execute();
NodeIterator it = res.getNodes();
if (it.hasNext()) {
Node n = it.nextNode();
//Check out the current node
n.checkout();
//Set a new property value for blogtext
n.setProperty("blogtext", new StringValue("Edited blog text"));
//Save the new version.
session.save();
//Check the new vesion in, resulting in a new item being added
//the the node's version history
n.checkin();
}
Jackrabbit tracks versioning through a special versioning data store. That data store works much like a regular workspace, and contains nodes that are of a special version history type. Reusing the regular Node object model for version metadata is a good example of how a repository's information model blurs the distinction between metadata and "regular" data.
For every versionable node, there is a hierarchy of version nodes, consisting of at least a single element denoting the current version. When the repository saves a new version, the old version's node data is added as a "frozen" child node of the versioning node. The following code example shows how we can retrieve all versions of a blog entry and display the changes occurring to the blogtext property:
//Obtain the blog node's version history
VersionHistory history = n.getVersionHistory();
VersionIterator ito = history.getAllVersions();
while (ito.hasNext()) {
Version v = ito.nextVersion();
//The version node will have a "frozen" child node that contains
//the corresponding version's node data
NodeIterator it = v.getNodes("jcr:frozenNode");
if (it.hasNext()) {
Node no = it.nextNode();
System.out.println("Version saved on " +
v.getCreated().getTime().toString() +
" has the following message: " +
no.getProperty("blogtext").getString());
}
}
Conclusion
Perhaps the biggest benefit of the JCR API is that it doesn't try to persist Java objects, and cares little about an application's object model. Instead, the JCR API focuses entirely on the content, or data, of an application. While this may at first sound like a step backwards, it actually creates a very clean and easy-to-use programming model with a sharp focus on a handful of data management tasks, such as versioning.
That is almost the exact opposite of object-relational or Java persistence APIs, which try to map an application's object model to some persistence schema, such as a relational database. The JCR API also differs from object-oriented databases, where the persistent representation of data is expressed in terms of the programming language's type system, and matches an application's object model.
Paradoxically, a big payoff in having a completely separate persistent data model and an application object model is the same relational databases first offered almost three decades ago: It allows the reuse of persistent schema from multiple application domains. For instance, having a blogging data repository available on the Web could allow a diverse set of applications to access that repository. Since nothing in that repository information model would be tied to a specific programming language, or even a specific kind of application design, such a repository would be analogous to a huge data "superstore" accessible to anyone permitted by the repository's security policies.
Such public data stores have been dreamt up before, the most the significant effort to date being the ebXML Registry [12]. However, while ebXML focuses on specifying metadata types for a variety of application domains, public repositories can in theory hold any information model.
Still, for a public blogging "superstore" to have real value to application developers, for instance, some agreement on the node types supporting a blogging data model would be helpful. The repository community has so far avoided the politically sensitive pitfalls of trying to initiate agreement about such information models. The jury is still out whether truly universal data "superstores" can emerge in the absence of such shared data models, or if they will remain a dream befitting Utopia.
Resources
[1] Thomas More's Utopia
http://www.ub.uni-bielefeld.de/diglib/more/utopia/
http://ota.ahds.ac.uk/texts/2080.html
[2] JCP home page for JSR 170, the Java Content Repository API:
http://www.jcp.org/en/jsr/detail?id=170
[3] The Java Community Process:
http://www.jcp.org/
[4] Day Software:
http://www.day.com/en.html
[5] Apache's Jackrabbit:
http://incubator.apache.org/jackrabbit/
[6] "Repositories and Object Oriented Databases," by Philip A. Bernstein:
http://www.sigmod.org/record/issues/9803/bernstein.ps
[7] Microsoft Repository:
http://msdn.microsoft.com/library/default.asp?url=...
[8] CVS:
http://www.gnu.org/software/cvs/
Subversion:
http://subversion.tigris.org/
[9] Sun's ZFS filesystem:
http://www.sun.com/2004-0914/feature/
[10] The Microsoft Windows WINFS file system:
http://msdn.microsoft.com/data/winfs/
[11] JCP 2.6:
http://java.sun.com/developer/technicalArticles/jcp/
[12] ebXML:
http://www.ebxml.org/
[See also] Document repositories:
http://www.manageability.org/blog/stuff/open-source-document-repository/view
A zip file containing the code example from this article (this is a large file because it also includes the JAR files you will need to run the example):
http://www.artima.com/lejava/articles/examples/rabbitblog.zip
Talk back!
Have an opinion? Readers have already posted 5 comments about this article. Why not add yours?
About the author
Frank Sommers is a Senior Editor with Artima Developer. He also serves as chief editor of the Web zine ClusterComputing.org, the IEEE Technical Committee on Scalable Computing's newsletter, and is an elected member of the Jini Community's Technical Advisory Committee. Prior to joining Artima, Frank wrote the Jiniology and Web services columns for JavaWorld.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)