
Build and Use Distributed Data Structures in Your JavaSpaces Programs
First published in JavaWorld, October 2000
The design of any space-based application typically revolves around one or more distributed data structures. These are data structures that exist in a space where multiple processes can access and work on them at the same time -- something that is often difficult to achieve in distributed computing models.
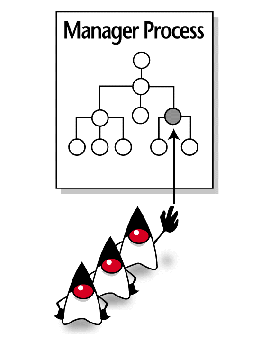
As Figure 1 below shows, message passing and remote method invocation systems usually sequester data structures behind a centralized manager process; therefore, any process that wants to manipulate the structures will have to wait its turn and ask the manager to perform the operation on its behalf. In other words, multiple processes can't truly access a data structure simultaneously in these conventional systems.
|
Figure 1. Conventional systems barricade data behind a centralized |
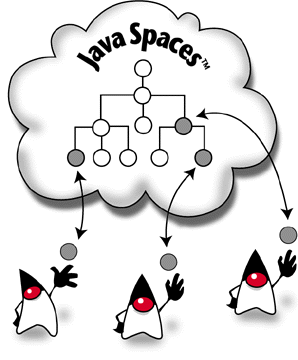
Distributed data structures take a very different approach that decouples the data from any one process. Distributed data structures are represented as collections of objects that, as I said earlier, can be accessed and modified by multiple processes concurrently. As Figure 2 suggests, processes can work on different pieces of the structure at the same time without getting in each other's way.
|
Figure 2. JavaSpaces supports concurrent access to distributed |
The design of any distributed data structure requires both a representation of the data structure and a protocol that processes follow to ensure that they can manipulate the structure safely and fairly. Now I'll explain how you can use entries to represent distributed data structures, and how you can use space operations to implement distributed protocols.
Build Distributed Data Structures with Entries
Let's say you want to store an array of values in a space, and that you'd like the array to be accessible and modifiable by multiple processes simultaneously. For example, suppose your array holds today's highest temperatures for all 50 US states, and that weather stations in the various states will need to read and alter the values throughout the day.
The first approach you might think up is to store the array in an entry, like this:
public class HighTemps implements Entry {
public Integer[] values;
public HighTemps() {
}
}
If a weather station wants to read or alter the high temperature for its state, it must read or remove the entire array. With this scheme, you haven't yet created a truly distributed array, since multiple processes cannot access or modify the array values simultaneously. The entry itself can become a bottleneck if many processes are trying to access the array concurrently.
You can try a different approach and decompose the temperature array into a collection of entries, each of which represents a single array element. Here's how you would represent an array element:
public class HighTemp implements Entry {
public Integer index;
public Integer value;
public HighTemp () {
}
public HighTemp(int index, int value) {
this.index = new Integer(index);
this.value = new Integer(value);
}
}
Each HighTemp entry has an index (the element's position in the array) and a value (the element's temperature value). Here's how to initialize a 10-element array (leaving out the try/catch clause for simplicity):
for (int i = 1; i <= 10 ; i++) {
HighTemp temp = new HighTemp(i, -99);
space.write(temp, null, Lease.FOREVER);
}
This loop deposits 10 HighTemp entries into the space, initializing each with an index and a value of -99. Here's how you would read one of the temperature entries -- the fifth one, in this example:
// create a template to retrieve the element
HighTemp template = new HighTemp();
template.index = new Integer(5);
// read it from the space
HighTemp temp = (HighTemp)space.read(template, null, Long.MAX_VALUE);
To modify that temperature, you take the temperature entry from the space (using the same template), update its value, and then write the entry back to the space as follows:
// remove the element
HighTemp temp = (HighTemp)space.take(template, null, Long.MAX_VALUE);
// alter the value
temp.value = new Integer(105);
// return the element to the space
space.write(temp, null, Lease.FOREVER);
This example demonstrates the basics of building and using a very simple distributed data structure. Since this distributed array is represented by multiple entries in the space, multiple processes can access and modify it concurrently -- for example, one process can modify element 0 without interfering with another process modifying element 48.
Along with the distributed data structure's representation, you've seen the protocol that processes follow to deal with the array. To read an array value, a process reads that value's entry in the space. To modify an array value, a process first takes the entry from the space, updates its value field, and then writes the entry back to the space. You could augment this ultra-simple protocol in various ways: for example, you could also store the size of the array, copy a value from one element to another, or delete an element.
While the distributed array data structure has a counterpart in the sequential programming world, you'll find that some distributed data structures are completely new. In the compute server example discussed in Part 2 and Part 4 of this series, you already encountered a distributed data structure that has no sequential analog: bags (which were used for holding task and result entries). Let's take a closer look.
Unordered Structures: Bags
Unlike sequential programs, space-based programs often make use of unordered data structures -- in other words, collections of objects. These collections are sometimes called bags, because they are like bags of objects. With ordered collections, you pinpoint and manipulate specific elements in the structure; with unordered collections, you perform just two basic operations: put (i.e., add a new object to the collection) and get (i.e., remove and return any object from the collection). Think of a box that holds raffle tickets. If you want to participate, you fill out a ticket with your information and just throw it into the box, without caring where it goes. When the contest is over, someone reaches into the box and grabs an arbitrary card -- any card will do. Bags are very easy to create in space-based programs: to create one, you simply define an entry class and write as many instances of that entry into the space as you want.
You've already seen the use of task bags and result bags in the compute server example earlier in this series. Recall from that example that a master process divides a large problem into a number of tasks and writes task entries into a task bag in the space. One or more worker processes look for these tasks, remove them from the space, compute them, and write result entries back into a result bag in the space. The master process looks for and collects these result entries and combines them into a meaningful result, such as a ray-traced image or decrypted password.
Besides their use in parallel computations, task and result bags can be used by processes to request and supply services without having to know exactly who they are requesting a service from or supplying a service to. For example, a process that needs some kind of service can drop a task entry into the task bag, and any available service that knows how to fulfill that task can pick it up, perform it, and write the result entry to the result bag, from which the original process will retrieve it.
Ordered Structures: Channels
When people first see the JavaSpaces API, they often ask, "How can I get a list of all the entries in a space?" It's a legitimate concern, since programmers often want to iterate over a set of objects. The simple answer is that the API itself provides no way to iterate over all the entries in the space. You can think of a space itself as just a big bag of entries -- an unordered collection of objects. The good news is that you can impose your own structure on a space by building various ordered distributed data structures within it. Once you've done this, entries can be enumerated by performing simple operations on those data structures.
In the remainder of this article, I'll explore how to create and work with one very useful type of ordered distributed data structure -- a channel. You can think of a channel as an information pipe that takes in a series of objects at one end and delivers them at the other end in the same order. At the input end, there may be one or more processes piping in messages or requests. At the output end, there may be one or more processes reading or removing these objects.
Channels turn out to be very versatile data structures, and can be used to achieve a variety of communication patterns in JavaSpaces programs (refer to Chapter 5 of JavaSpaces Principles, Patterns, and Practice for more details). In the rest of this article, I'll walk step-by-step through the details of implementing one kind of channel distributed data structure, and show you how it is central to a real-world program -- a distributed MP3 encoding application. Before diving down into the details, I'll give an overview of the application we'll be building.
A Distributed MP3 Encoding Application
Most folks have heard of MP3, a wildly popular sound compression format. Sounds encoded in MP3 format almost match CDs in quality, but MP3 files are much smaller than the equivalent files on a CD. If you've ever played around with digital audio files, you may have performed encoding -- the process of taking uncompressed digital audio data (for example, wav files on your PC) and compressing them according to a specific compression scheme such as MP3. MP3 encoding can be a computationally intensive process, especially if the original wav file is large or you have a large collection of wav files to encode.
You might imagine submitting your wav files to a high-powered, net-connected MP3 encoding service that would perform the wav-to-MP3 encoding for you and return the MP3 data. If many users simultaneously send encoding requests to a single MP3 encoder, the requests would need to queue up until they could be serviced. However, since the encoding tasks are completely independent of each other, they lend themselves well to being serviced in parallel by a farm of MP3 encoders. By using a space, you can easily build a distributed MP3-encoding application; Figure 3 shows the architecture of the system.
|
Figure 3. The architecture of the distributed MP3-encoding application |
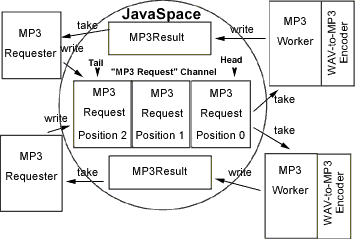
At first, you might think that your distributed application should just use bags, as the compute server did. In other words, the application could revolve around a bag of MP3 requests (deposited by MP3Requester processes and picked up by MP3Worker processes) and a bag of MP3 results (deposited by MP3Workers and picked up by MP3Requesters). This scheme has one major drawback: there is no guarantee of fairness. In other words, there's no assurance that some newer encoding requests won't be serviced before older requests. In fact, some requests might languish forever and never get picked up, while others are serviced. Ideally, you'd like for encoding requests to be handled on a first-come, first-served basis, with a guarantee of eventually being serviced (provided that at least one MP3 worker remains up and running to perform encoding). It turns out that a channel distributed data structure is exactly what you need to accomplish those goals.
As you can see from Figure 3, MP3Requester processes add MP3 encoding requests to the tail end of an MP3 Request channel, and MP3Worker processes take the requests off the head end of the channel, in order. An MP3Worker calls a piece of third-party software to perform the actual wav to MP3 encoding; when that software generates the MP3 data, the worker writes the data to a result bag in the space (you can assume for this example that the order in which results are picked up is not important). In the meantime, the MP3Requester processes constantly monitor the space to pick up and display results that have been tagged for them.
Now that you have the aerial view of the application, I'll dive down into the details.
The MP3 Request Channel
To implement the MP3 Request channel, you use an ordered collection of MP3Request entries -- one for each request in the channel. Each MP3Request entry holds its position in the channel. For instance, the third request to be added to the channel has a position of three (assuming that the request sequence starts at one).
Requests are added to the tail end of the channel, and taken away from the head end. You can use a tail entry to keep track of the end of the channel: it holds the position number of the last request in the channel, and it gets incremented before you append a new request to the channel. You'll also need a head entry to keep track of the front of the channel: it holds the position number of the first request in the channel, and every time a request is removed from the front, the head's position number is incremented to point to the next request.
Now I'll show how each MP3Request in the channel will look.
The MP3 Request Entry
The MP3Request entry is defined as follows:
public class MP3Request implements Entry {
public String channelName; // recipient of the request
public Integer position; // position # of request in channel
public String inputName; // file path
public byte[] data; // content of the file
public String from; // who sent the request
public MP3Request() { // the no-arg constructor
}
public MP3Request(String channelName) {
this.channelName = channelName;
}
public MP3Request(String channelName, Integer position) {
this.channelName = channelName;
this.position = position;
}
public MP3Request(String channelName, Integer position,
String inputName, byte[] data, String from)
{
this.channelName = channelName;
this.position = position;
this.inputName = inputName;
this.data = data;
this.from = from;
}
}
Each MP3Request entry contains five fields: channelName, position, inputName, data, and from. The channelName identifies the name of the channel to which the request belongs (which in this example will always be "MP3 Request"). The position field specifies the integer position of the request in the channel. The inputName holds the absolute path name to a wav file to encode (for example, C:\Windows\Desktop\groovy-music.wav). The data field is used to hold the raw byte content of that file. Finally, the from field specifies the user who submitted the request.
Tracking the Channel's Start and End
You'll need both head and tail entries to keep track of the front and back ends of the channel, respectively. You can base both on the Index entry defined here:
public class Index implements Entry {
public String type; // head or tail
public String channel;
public Integer position;
public Index() {
}
public Index(String type, String channel) {
this.type = type;
this.channel = channel;
}
public Index(String type, String channel, Integer position) {
this.type = type;
this.channel = channel;
this.position = position;
}
public Integer getPosition() {
return position;
}
public void increment() {
position = new Integer(position.intValue() + 1);
}
}
The Index entry has three fields: a type field to identify the type of index (whether the entry points to the head or tail of the channel), a channel field that holds the name of the channel, and a position field that contains the position number (of the head or tail element). You'll notice that this entry has three constructors and two convenience methods: getPosition, which returns the position of the head or tail, and increment, which increments the position by one.
You'll track the start and end of the channel using Index entries as follows. Say your channel holds five MP3Request entries, at positions one through five. In that case, the head index entry will hold position number one, and the tail index entry will hold position number five. When a new request is added to the tail end of the channel, the tail position is incremented by one. When a request is removed, it is taken away from the head end of the channel, which results in the head position being incremented by one. If requests are removed at a faster clip than new ones are added, eventually there will be just one request in the channel, with both the head and tail pointing to it. If that one remaining request is removed and the head is incremented, the head's position number will be greater than the tail's -- and that will indicate an empty channel. As long as the tail position is greater than or equal to the head position, you know there are requests in the channel.
Creating the MP3 Request Channel
Now I'll show how you create your (initially empty) channel. An administrator runs a ChannelCreator application, which is defined like this:
public class ChannelCreator {
private JavaSpace space;
public static void main(String[] args) {
ChannelCreator creator = new ChannelCreator();
creator.createChannel(args[0]);
}
private void createChannel(String channelName) {
space = SpaceAccessor.getSpace();
Index head =
new Index("head", channelName, new Integer(1));
Index tail =
new Index("tail", channelName, new Integer(0));
System.out.println("Creating new channel " + channelName);
try {
space.write(head, null, Lease.FOREVER);
space.write(tail, null, Lease.FOREVER);
} catch (Exception e) {
System.out.println("Error creating the channel.");
e.printStackTrace();
return;
}
System.out.println("Channel " + channelName + " created.");
}
}
Notice that ChannelCreator takes as an argument the name of the channel to be created, which in this case is "MP3 Request." When this application is run, the main method takes the channel name and passes it to the createChannel method. The job of createChannel is straightforward: it sets up two Index entries to mark the head and tail of the channel, and it writes them to the space. Since a new channel starts out empty, createChannel sets up the tail entry with an index of zero and the head entry with an index of one (recall that when the tail position is less than the head position, you know you have an empty channel).
The MP3 Requester
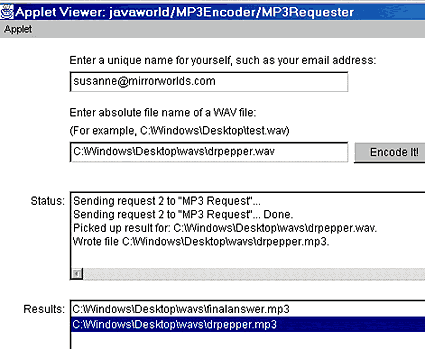
Once a channel exists, you are free to add requests to it. In order to add MP3 encoding requests to your MP3 Request channel, you run an MP3Requester applet, whose interface is shown in Figure 4. To request MP3 encodings, you must fill in the topmost text field with a unique name that identifies yourself (you can use your email address, for example); this name will be used to identify your requests and results. You must also fill in the text field that asks for an absolute filename (say, C:\Windows\Desktop\wavs\drpepper.wav) that you'd like to have encoded. Then you're ready to click on the Encode It! button, which causes the MP3Requester to append the request to the MP3 Request channel.
|
Figure 4. The MP3Requester GUI |
Here's the code skeleton for the MP3Requester applet:
public class MP3Requester extends Applet
implements ActionListener, Runnable
{
private JavaSpace space;
private Thread resultTaker;
private String from; // unique name for person requesting MP3s
. . . variables for user interface components
public void init() {
space = SpaceAccessor.getSpace();
// spawn thread to handle collecting & displaying results
if (resultTaker == null) {
resultTaker = new Thread(this);
resultTaker.start();
}
. . . user interface setup
}
// "Encode It!" button pressed
public void actionPerformed(ActionEvent event) {
from = userTextField.getText();
String inputName = fileTextField.getText();
. . .
// we'll package the file's raw data in the entry
byte[] rawData = null;
rawData = Utils.getRawData(inputName); // open file & read bytes
// append an MP3 request to the channel
if (rawData != null) {
append("MP3 Request", inputName, rawData, from);
}
}
. . . append method goes here
// thread that loops, taking & displaying MP3 results
public void run() {
. . .
}
}
Whenever the Encode It! button is pressed, the actionPerformed method gets called to add the MP3 encoding request to the MP3 Request channel. This method first extracts the unique username and the filename that you typed into the applet's text fields. The method opens the wav file and obtains its raw byte data. Then the append method (which I'll explain shortly) is called to add the request to the channel, passing it the name of the channel ("MP3 Request"), the filename to encode, the raw data from the file, and the name of the user making the request.
Another thing to note about this applet is that it spawns a result taker thread. The run method of this thread loops continuously, removing MP3 results from the space and displaying the resulting MP3 filenames in the applet's GUI. (This functionality needs to run in its own thread, since the main thread of the applet needs to be available and responsive to GUI events such as button clicks.)
Appending a Request to the Channel
Let's take a closer look at the append method that adds requests to the tail end of a channel. That method obtains the position number of the tail, increments it, and stamps the new request with that number.
First, you'll define a getRequestNumber method that obtains a position number for the new request:
private Integer getRequestNumber(String channel) {
try {
Index template = new Index("tail", channel);
Index tail = (Index) space.take(template, null, Long.MAX_VALUE);
tail.increment();
space.write(tail, null, Lease.FOREVER);
return tail.getPosition();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
In this method, you first create an Index template, specifying that you're looking for a tail index in a certain channel (but leaving the position number unspecified, to serve as a wildcard). Then you call take to remove the tail entry for that channel, waiting as long as necessary. Once you've retrieved the tail entry for the channel, you increment the tail and write it back into the space. You return the new position number of the tail to the caller, to be used as the position number of the new request. Since the tail entry for a channel starts out at position zero, the first time you call this method for a channel, position one will be returned to use for the first request.
Now you'll make use of getRequestNumber to implement the append method:
private void append(String channel, String inputName,
byte[] rawData, String from) {
Integer num = getRequestNumber(channel);
MP3Request request =
new MP3Request(channel, num, inputName, rawData, from);
try {
space.write(request, null, Lease.FOREVER);
} catch (Exception e) {
e.printStackTrace();
return;
}
}
The append method takes the name of the channel ("MP3 Request"), the filename to encode, the raw data from the file, and the name of the user making the request. Here you first call getRequestNumber, passing it the channel name, to increment the tail and obtain a position number for the new request. Then you create a new MP3Request entry (with the given channel name, position number, filename, raw data, and user's name) and write it into the space.
Now that you've seen the details of the MP3 Requester and examined how it appends new MP3 encoding requests to your MP3 Request channel, we'll investigate what happens to those requests in the channel.
The MP3 Workers
An administrator will start up one or more MP3 workers. Each worker repeatedly removes an MP3 encoding request from the channel's head, calling a third-party program to perform the wav-to-MP3 encoding, and then constructs and writes an MP3Result entry into the space (which all MP3 Requesters are monitoring). Here's the basic outline of the MP3Worker code:
public class MP3Worker {
private JavaSpace space;
private String channel;
public static void main(String[] args) {
MP3Worker worker = new MP3Worker();
worker.startWork();
}
public void startWork() {
space = SpaceAccessor.getSpace();
channel = "MP3 Request";
while(true) {
processNextRequest();
}
}
. . . other method definitions
}
As you can see from the main and startWork methods, the worker enters a loop, in which it continually calls the processNextRequest method, which is defined as follows:
private void processNextRequest() {
Index tail = readIndex("tail", channel);
Index head = removeIndex("head", channel);
if (tail.position.intValue() < head.position.intValue()) {
// there are no requests
writeIndex(head);
return;
}
// get the next request & increment the head:
MP3Request request = removeRequest(channel, head.position);
head.increment();
writeIndex(head);
if (request == null) {
System.out.println("Communication error.");
return;
}
// retrieved an MP3 request, so call third-party freeware
// program to perform the conversion from WAV to MP3
String inputName = request.inputName;
byte[] inputData = request.data;
byte[] outputData = null;
String tmpInputFile = "./tmp" + request.position + ".wav";
String tmpOutputFile = "./tmp" + request.position + ".mp3";
Process subProcess = null;
Utils.putRawData(inputData, tmpInputFile);
try {
String[] cmdArray = { "\"C:\\Program Files\\BladeEnc\\BladeEnc\"",
"-quit", "-quiet", "-progress=0", tmpInputFile, tmpOutputFile};
subProcess = Runtime.getRuntime().exec(cmdArray);
subProcess.waitFor();
} catch (Exception e) {
. . .
return;
}
. . .
// put MP3 result into the space
outputData = Utils.getRawData(tmpOutputFile);
MP3Result result = new MP3Result(inputName, outputData, from);
try {
space.write(result, null, Lease.FOREVER);
. . .
} catch (Exception e) {
. . .
return;
}
}
The processNextRequest method first reads the tail index for the MP3 Request channel, but leaves it in the space. Then it removes the head index and compares the two positions. If the tail's position is less than the head's position, that means the channel is currently empty and there are no encoding requests to process. If that is the case, this method simply returns the unmodified head index to the space and returns.
However, if there are requests in the channel, processNextRequest calls removeRequest to remove the request entry at the head, increments the head index, and then writes the updated head index back into the space. Then the method is ready to obtain the wav data from the request entry and perform the actual conversion. Let's look at how that happens.
The method extracts the input filename and wav input data from the request entry. It also constructs two temporary local files -- one to hold the wav input data and one to hold the MP3 output data -- and writes the wav input data into the temporary input file. Next the method makes a call to an external, third-party freeware program that takes the wav input file, encodes it into the MP3 format, and writes the resulting MP3 data to the temporary output file.
At that point, our method constructs an MP3Result (which I'll look at shortly) using the generated MP3 data, and writes it to the space.
For the sake of completeness, here are the definitions of a few helper methods used in the code. Their implementations should be fairly straightforward:
// remove a request entry from the channel
private MP3Request removeRequest(String channel,
Integer position)
{
MP3Request template = new MP3Request (channel, position);
MP3Request request = null;
try {
request = (MP3Request)
space.take(template, null, Long.MAX_VALUE);
return request;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
// remove an index ("head" or "tail") from the channel
private Index removeIndex(String type, String channel) {
Index template = new Index(type, channel);
Index index = null;
try {
return (Index)space.take(template, null, Long.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
// read an index ("head" or "tail") from the channel
private Index readIndex(String type, String channel) {
Index template = new Index(type, channel);
Index index = null;
try {
return (Index)space.read(template, null, Long.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
// write a head or tail index to the channel
private void writeIndex(Index index) {
try {
space.write(index, null, Lease.FOREVER);
} catch (Exception e) {
e.printStackTrace();
}
}
The MP3Result Entry
As the workers obtain MP3 data, they wrap the results in MP3Result entries and write those into the space for MP3 Requesters to find. Here's how an MP3Result entry is defined:
public class MP3Result implements Entry {
public String inputName; // name of file that was encoded
public byte[] data; // raw MP3 data
public String from; // who sent the request
public MP3Result() { // the no-arg constructor
}
public MP3Result(String from) {
this.from = from;
}
public MP3Result(String inputName, byte[] data, String from) {
this.inputName = inputName;
this.data = data;
this.from = from;
}
}
The result entry is straightforward: it holds the filename that was encoded, the bytes representing the MP3 encoding, and a String representing the name of the person who requested the MP3.
Collecting and Displaying the MP3 Results
As I mentioned earlier, each MP3 Requester has a thread that loops continuously, removing MP3 results from the space and displaying them. To complete your understanding of the whole picture, here's the code that accomplishes this:
// thread in the MP3Requester that loops,
// taking & displaying links to MP3 results
public void run() {
MP3Result template = new MP3Result(from);
MP3Result result = null;
String outputName = ""; // name of MP3 output file
while(true) {
try {
result = (MP3Result)
space.take(template, null, Long.MAX_VALUE);
int pos = result.inputName.indexOf(".wav");
outputName = result.inputName.substring(0, pos) + ".mp3";
Utils.putRawData(result.data, outputName);
displayResult(outputName);
} catch (Exception e) {
e.printStackTrace();
}
}
}
This method first constructs an MP3Result template, supplying only the username that was entered into the requester's GUI. Then the method enters a loop, looking for any MP3Result entries that are tagged with the requester's name. Whenever an entry is found, it is removed from the space, and the raw MP3 data is written to an output file that corresponds to the input file the user specified. For instance, if the user specified C:\Windows\Desktop\wavs\drpepper.wav as the file to encode, the resulting MP3 data is written to C:\Windows\Desktop\wavs\drpepper.mp3. Then displayResult is called to display the name of the file in the GUI (see the results area of Figure 4); if the user double clicks on the MP3 filename, an MP3 player (currently hardcoded in the application as C:\Program Files\winamp\winamp) will be launched to play the MP3 file.
Wrapping it Up
With this article, we've created a real-world distributed application that revolves around two distributed data structures -- an ordered MP3 Request channel holding MP3Request entries, and an unordered bag holding MP3Result entries. The channel distributed data structure is versatile; with small changes to the protocols, it can form the basis of a variety of communication patterns. For instance, if workers don't remove the entries in the channel but simply read them, the channel can form the basis of an archived chat stream in the space. To explore channels further, refer to JavaSpaces Principles, Patterns, and Practice.
You might think of the pattern in this example as a variation on the master/worker pattern Eric Freeman and I used in earlier columns. Recall that, in the master/worker pattern, a single master process deposits tasks into a task bag in the space, and worker processes pick up arbitrary tasks, compute them, and write the results into a result bag. Now, in our MP3 encoder architecture, there are potentially many requester processes that append requests to an ordered channel of requests, and potentially many workers that pick up the requests in order and process them. Just as in the master/worker pattern, the workers write the results into a result bag in the space. The requester processes pick up just the results earmarked for them. You could apply the pattern developed here to a wide variety of domains: writers simply add tasks (or requests for services) to the channel, and worker processes remove and process the tasks (computing them or providing some other service). The channel distributed data structure allows requests to be processed in a fair, first-come, first-served manner.
It's also worth noting, once again, that space-based communication decouples the senders and receivers of information and promotes a loosely coupled communication style in which senders and receivers don't interact directly, but rather communicate through distributed data structures in a space. In this distributed MP3 encoding example, the requesters don't care which worker or backend server ultimately processes their request; they only care that they get a result back. Conversely, the workers don't care who wants MP3 data; they just know how to take the request and deliver a result back to the space. Loosely coupled applications tend to be more flexible and scalable than tightly coupled ones. Indeed, in this case you can deploy as many workers on as many machines as you would like, without revising or recompiling any code.
Distributed data structures are the building blocks of space-based distributed programs. There is no limit to the variety and complexity of distributed data structures you can build using entries: distributed linked lists, hierarchical tree structures, graphs, and so on. Now that you've seen a few distributed data structures and their power, you should be ready to start inventing new and useful structures for your own applications.
Resources
- Download the source code for this example (with the exception of the third-party software):
http://www.javaworld.com/jw-10-2000/javaspace/code.zip
- Download a third-party freeware MP3 encoder:
http://bladeenc.mp3.no/
- Read the whole "Make Room for JavaSpaces" series:
- Part 1. Ease the development of distributed apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js1.html
- Part 2. Build a compute server with JavaSpaces:
http://www.artima.com/jini/jiniology/js2.html
- Part 3. Coordinate your Jini apps with JavaSpaces:
http://www.artima.com/jini/jiniology/js3.html
- Part 4. Explore Jini transactions with JavaSpaces:
http://www.artima.com/jini/jiniology/js4.html
- Part 5. Make your compute server robust and scalable:
http://www.artima.com/jini/jiniology/js5.html
- Part 6. Build and use distributed data structures in your JavaSpaces programs:
http://www.artima.com/jini/jiniology/js6.html
- Part 1. Ease the development of distributed apps with JavaSpaces:
- For a more in-depth exploration of space-based programming concepts and distributed data structures, as well as a detailed look at the JavaSpaces technology APIs, refer to Sun's official Jini Technology Series book on the topic: JavaSpaces Principles, Patterns, and Practice, Eric Freeman, Susanne Hupfer, and Ken Arnold (Addison-Wesley, 1999):
http://www.amazon.com/exec/obidos/ASIN/0201309556/
- You may wish to experiment with the code from JavaSpaces Principles, Patterns, and Practice, which is downloadable from the book's Website:
http://java.sun.com/docs/books/jini/
- For information about getting your JavaSpaces (or Jini) programs up and running, refer to "The Nuts and Bolts of Compiling and Running JavaSpaces Programs," Susanne Hupfer (Java Developer Connection, January 2000):
http://developer.java.sun.com/developer/technicalArticles/Programming/javaspaces
- Whether you wish to share information with other developers (including the Sun engineers that developed the Jini and JavaSpaces technologies), or seek troubleshooting advice, the official JavaSpaces-users mailing list is the place to go:
http://archives.java.sun.com/archives/javaspaces-users.html
- Receive ITworld.com's Jini Advisor, a free weekly newsletter focusing on Jini:
http://www.itworld.com/cgi-bin/w3-msql/newsletters/subcontent12.html
- The Jini-users mailing list also has a considerable amount of JavaSpaces-related discussion:
http://archives.java.sun.com/archives/jini-users.html
- For pointers to the JavaSpaces FAQ and other documentation, refer to the Sun Microsystems JavaSpaces page:
http://java.sun.com/products/javaspaces/
- For a complete listing of all previous Jiniology columns:
http://www.javaworld.com/javaworld/topicalindex/jw-ti-jiniology.html
"Make Room for JavaSpaces, Part IV" by Susan Hupfer was originally published by JavaWorld (www.javaworld.com), copyright IDG, October 2000. Reprinted with permission.
http://www.javaworld.com/javaworld/jw-10-2000/jw-1002-jiniology.html
Talk back!
Have an opinion? Be the first to post a comment about this article.
About the author
Dr. Susanne Hupfer is director of product development for Mirror Worlds Technologies, a Java- and Jini-based software applications company, and a research affiliate in the department of computer science at Yale University, where she completed her Ph.D. in space-based systems and distributed computing. Previously, she taught Java network programming as an assistant professor of computer science at Trinity College. Susanne coauthored the Sun Microsystems book JavaSpaces Principles, Patterns, and Practice.
Artima provides consulting and training services to help you make the most of Scala, reactive
and functional programming, enterprise systems, big data, and testing.
2070 N Broadway Unit 305
Walnut Creek CA 94597
USA
(925) 918-1769 (Phone)